분산시스템에서 동기화문제는 하나의 컴퓨터에서 돌아가는 것보다 더 어렵다. 여러 컴퓨터들이기 때문에
Clock synchronization
두 컴퓨터의 시간동기화를 맞추지 않았을때 발생한 예시 : make compiler(대규모일 경우 컴파일하기 까다로워서 이것을 대신해 주는 컴파일러)

컴퓨터에서 돌아가는 시간정보에 대해서 알아보자.
컴퓨터내에 시간정보가 있다. timer가 있는데 quartz crystal에 전기신호를 주어서 진동을 만든다. 이 진동신호가 주기적으로 발생해서 이진동이 몇 번 일어날 때마다 인터럽트를 발생시켜서 카운트값을 하나씩 줄인다. 그래서 주기적으로 인터럽트를 발생시키고 인터럽트가 몇 번 쌓일 때마다 1초로 치자. 한 번의 인터럽트가 발생하는 것을 clock tick라고 한다. 그런데 컴퓨터마다 이러한 주기가 다 다르기 때문에 시간이 각각 다르게 나온다.(time difference가 발생할 수밖에 없다.) 그래서 시간상의 diffrenece차이를 clock skew라고 한다.
UTC는 완전한 정확한 시간은 아님(대충). 왜냐하면 웹브라우저에서 보는 시간 정보는 어딘가에서 네트워크를 타고 날라온 시간 메시지를 출력하는 것이기 때문에 transmission 딜레이를 고려해야 한다. 그래서 컴퓨터시간을 정확히 맞추는 것이 까다롭다.
전서계에서 이 시간을 어떻게 맞췃냐면 solar time으로 측정을 했다. 해가 제일 높게 떴을 때를 기준으로 제고 그다음 날 가장 높은 곳에 뜨면 하루라고 지정을 하고 그 전체시간을 86400으로 나는 것을 1초라고 했었다. 그런데 태양의 고도도 매번 다르기 때문에 정확하지는 않았다. 그래서 1948년에 개발된 international Atomic time(TAI)을 사용했다. 이 주기는 원자의 주기를 가지고 같은 방식으로 측정했다. 이놈은 굉장히 정확해서 표준시로 정하기로 했음. solar와 TAI를 돌렸더니 두 시계의 차이가 3밀리 세컨드가 났다. 이것을 계속 놔두면 점점시간차이가 나기 때문에 solar time을 다시 제조 정했었더. 이과정을 leap seconds과정이라고 한다.

그래서 동일한 시간을 측정하기위한 표준시 정책을 사용했다.
UTC(universal coordinated time) : TAI의 정보를 이용해서 표준시를 마련한 것. 옛날에는 GMT(greenwich mean time)를 사용해서 사용했었음, NIST라는 대서 shortwave radio station을 통해서 전파를 받거나 인공위성을 통해서 정확한 정보를 받을 수 있다.


그렇지 않은 시계라면 동기화하기가 어렵고 시계의 역할을 수행하기가 어렵다. 그래서 NTP 프로토콜을 이용해서 시간을 동기화 해보자. 개념은 동기화하고자 하는 컴퓨터는 시간정보를 갖고 있는 대상에게 시간이 몇이냐고 물어보고 그 시간 정보를 가지고 딜레이 값을 고려해서 나의 시간정보를 보정하는 것이다.
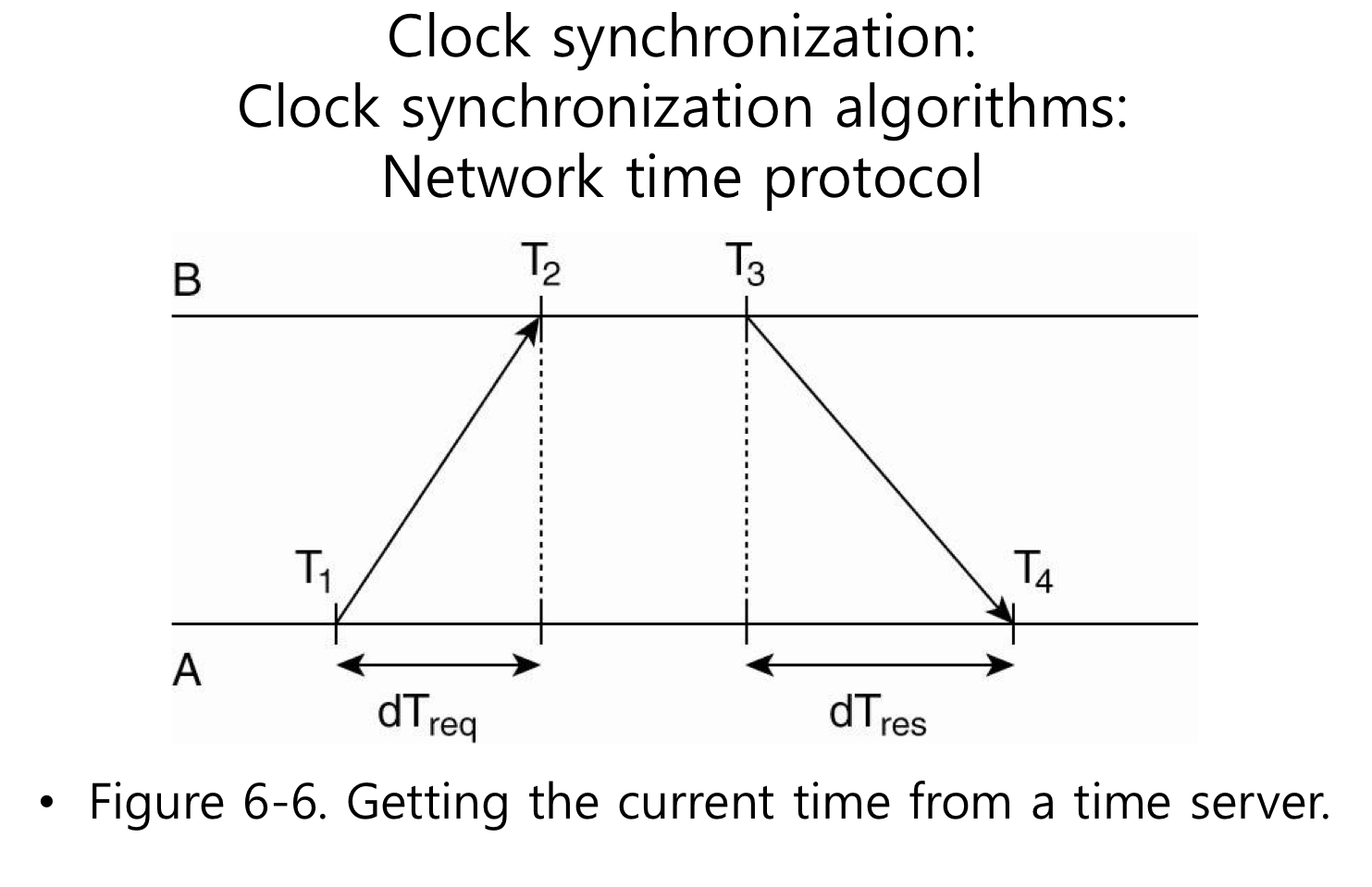

그런데 내가 시간이 더 빠르다고 시간을 빼서 과거로 돌리는것도 이상하다. 그래서 시간을 확 빼지 말고 시간의 변화량을 늦춰서 시간을 맞추자. 시간이 늦다면 변화량을 증가시키자. 그래서 점차 시간이 맞도록 하자.
시간이 가는 속도를 늦추는 방법인 예시 : 시간이 1초라는 시간안에 100번의 인터럽트가 발생한다고 가정한다면(즉, 1번의 인터럽트가 발생하면 시간이 10 msec가 지나간 것, 즉 10번 인터럽트가 발생할 때마다 10 msec를 더한다, 100번의 인터럽트라면 1000 msec가 지나간 것이라고 체크할 수 있다.) 시간의 값을 빼는 것이 아니라 9 msec만 더한다면 시간값이 덜 더해지므로 시간값이 늦춰질 수 있다. 시간이 느리다면 11 msce를 주자.
NTP(network time protocol) : 나보다 정확한 시간을 알고 있는 서버에게 물어보는 방식
어떤 룰이 없다면 임의의 컴퓨터에게 물어봐야하는데 그 컴퓨터가 더 부정확할 수 도 있어서 문제가 발생할 수 있음. 이 문제를 해결하기 위해서 시간의 정확도를 단계별로 나누자. 이것을 strata라고 한다. strata의 값이 낮을수록 정확도가 높은 서버이다. 그래서 컴퓨터들 간의 strata값을 비교해서 나보다 정확한지 부정확한지 알 수 있다.
NTP와 반대되는 또다른 알고리즘으로 Berkeley 알고리즘이 있다. 이것도 컴퓨터들 간의 시간을 똑같이 맞춘다는 개념은 비슷하다. NTP는 서버에게 물어봐서 시간을 동기화하는 방식이었다면 버클리 알고리즘은 시간이 정확한 놈이 다른 클라이언트에게 시간을 물어본다. 그래서 다른 클라이언트들이 시간을 얼마큼 보정해야 하는지 알려주는 방식이다. 정리하면 NTP는 클라이언트가 서버에게 물어보는 거고 berkeley는 서버가 클라이언트에게 물어보는 방식이다. 그럼 어떻게 서버는 클라이언트에게 물어봐서 동기화를 할까?

즉, 버클리 알고리즘은 우리끼리만 시간을 맞추자는 것이다.
처음에는 UTC에 모든 시간을 맞추차고 생각했으나 만약 특정 컴퓨터들끼리만 한다면 굳이 모두 UTC에 맞춰야 하나? 그냥 이벤트의 발생 순서만 맞춘다면 문제가 없는 것은 아닐까? 그래서 시간동기화의 조건을 완화시킨 logical clocks이 나오게 되었다.
기존의 시계들은 시간동기화를 주기적으로 해야하고 그만큼 발생하는 오버헤드가 들기 때문에 컴퓨터들 간의 시간관계를 똑같이 맞추려고 하지 말고 발생하는 이벤트들의 순서관계만 찾기 위해서 만들어진 것이 logical clock이다. logical clock은 real time처럼 주기적으로 발생하는 것이 아니라 이벤트가 발생할 때마다 시간값을 증가시키겠다는 것이다. 그렇기 때문에 이벤트들 간의 시간관계를 Happens-before관계라고 정의했다. ex) a -> b (a happens before b) : a다음에 b가 발생했다. 모든 컴퓨터들이 동일하게 a가 b보다 먼저 발생했다는 것을 합의할 수 있으면 happens before관계가 만족이 된다.
순서관계를 잘 모르는 이벤트들은 빼고 확실하게 알 수 있는 관계들에 대해서만 정의를 하자.
1. 만약 a와b가 같은 프로세스에서 발생한 이벤트라면 당연히 a는 b보다 먼저 발생했다고 해서 happens before관계가 만족이 된다.
2. a라는 이벤트는 메시지를 보내는 이벤트고 b는 메시지를 받았다는 이벤트이다. a와 b는 다른 프로세스라고 하더라고 a는 보내는 거고 b는 받는 거니 당연히 보낸 다음에 받을 수밖에 없기에 happens before관계가 성립이 된다.
happens before관계는 transitive 관계이다.(a이면 b이고 b이면 c이다 라는것이 맞다면 a는 c라는 관계가 성립이 된다)
만약 x, y가 서로다른 프로세스에서 발생하고 두 개의 이벤트가 아무런 연관관계가 없고 독립적이라면 이 두 개의 이벤트들은 concurrent 한 이벤트라고 할 수 있다.
C(a) : a라는 이벤트에 해당하는 logical clock의 값. 그래서 이것을 가지고 모든 컴퓨터들이 동일한 순서로 이벤트가 발생했다는것을 판단할 수 있게끔 logical clock을 디자인해보자.
만약 a와 b가 같은 프로세스에서 발생한 이벤트라면(a가 b보다 먼저 발생한 게 확실하다면) C(a) < C(b)가 성립이 되어서 logical clock의 값이 더 큰 게 늦게 발생했다는 이벤트라는 것을 알 수 있다. 만약 서로 다른 프로세스에서 a가 보내고 b가 받는 이벤트라면 C(a) < C(b)가 성립된다. 즉, happens before관계가 성립이 되는 이벤트들 간에는 먼저 발생한 이벤트의 logical 값이 작아야 한다.

그래서 이러한 조건을 만족하기 위해서 lamport의 logical clock에서 설정한 룰이 있다.
logical clock의 값을 어떻게 업데이트할 것인가?
1. 초기값은 0에서 시작하고 이벤트가 발생할 경우에 이벤트를 실행하기 전에 나의 logical clock값을 하나 증가시키자.
2. 만약 이벤트들 중에서 Pi라는 프로세스가 Pj에게 m이라는 메시지를 보내는 이벤트가 발생했다면 m이라는 메세지의 timestamp(메세지가 보내지는 시간 값)는 Ci라고 표시한다. 그래서 Pi가 Pj에게 m이라는 메세지를 보내는 이벤트가 발생할때마다 Pi의 Ci의 값이 하나씩 증가를 하는데 m이라는 메세지안에는 Ci의 logical clock의 값을 넣어서 보낸다. 즉 m안에는 Ci의 값이 들어가 있다,
3. 메세지를 받았을 경우에는 무조건 1을 증가시키면 안 되고 나의 logical clock값을 조절하자. Cj <- max {Cj, ts(m)} 이 조건을 이용하자. 즉, 나의 logical clock값과 메세지안에 담긴 Ci값을 비교해서 더 큰 놈을 선정을 해라 그다음에 그 선정한 놈 애 +1을 하자. 위의 그림을 예로 본다면 48과 60을 비교해서 더 큰 놈인 60을 선정을 하고 거기에 1을 더하자.
아래는 위 설명의 또 다른 예제이다.


여기서 조심해야 할 것은 모든 이벤트에 대해서 logical clock값만 가지고 어떤 이벤트가 먼저 발생했는지는 알 수 없다. happens before관계가 존재하는 이벤트에 대한 값만 비교를 하자. b와 j 중에서 누가 먼저 발생했는지 알 수 없다. happens before관계가 존재하는 이벤트들 간의 관계에서는(k와 h) 누가 먼저 발생했는지 알 수가 있음. e와 k 그리고 c와 h는 concurrent라고 할 수 있음.
lamport's logical clock의 또 다른 예제론 Totally ordered multicasting이 있다.
뉴욕(NY)과 샌프란시스코(SF)에서 복제된 내 계좌에 괜한 오퍼레이션이 발생했다고 가정하자. 두 개의 지역에서 동시에 이벤트가 발생한다라고 하자. 나의 현재 계좌에는 1000달러가 있다. SF에서는 내 계좌에 100달러를 더하고 NY에서는 내 계좌의 1퍼센트만큼 이자를 추가한다고 하자. 100달러를 더하고 1퍼센트의 이자를 주는 거와 그것의 반대행위를 하게 될 경우에 계좌 안에 금액은 1110원이 나오거나 1111원이 나오는 경우가 나올 수가 있다.

이러한 문제를 해결하기 위해서 totally-ordered multicast가 있다. 이것은 모든 메시지를 다 순서를 짓겠다는 뜻이다. 즉, 메세지를 받았다고 바로 처리하면 안 되고 나보다 먼저 처리해야 되는 메시지가 있나 없나 확인을 하고 처리해야 한다.
여기서 사용할 알고리즘
모든 업데이트 메시지는 메세지를 만들어서 보내는 쪽에 logical time정보를 넣어서 보낸다.
모든 업데이트 메세지는 멀티캐스트 된다.(나도 받음)
메시지를 받았을 경우에 받는애는 메세지를 local queue에 저장을 하고 이 메세지들안에 담겨있는 timestamp정보를 토대로 순서를 짓는다. 그 후에 모든 사이트로부터 acknowledgment (동의)메세지를 받고나서 queue안에 메세지를 실행한다.
totally ordered multicasting에서의 핵심은 acknowledgment메시지를 보내는 것이다. 메세지는 queue의 헤드에 있고 다른 노드들에게 acknowledgement메세지를 받을 경우애 그 메세지를 실행할 수 있다. 그럼 ack메세지를 보낼거냐 말거냐를 판단해야하는데 이판단기준은 3가지중에 하나라도 성립시 가능하다.
1. Pi가 업데이트 메세지를 받았을 때 나는 업데이트 태스크를 수행하지 않은 상태일 때
2. 내가 업데이트 메시지를 만들었고 그게 실행이 되지 않은 상태에서 다른 노드가 업데이트 메세지를 보냈을 경우 순서를 정해야한다. Pi의 프로세스 ID가 메세지를 보낸 Pj의 프로세스ID보다 크다면(프로세스ID값이 작을수록 우선순위가 높다) 내가 진거라서 받은 메세지를 먼저 수행해야하니 동의의 의미로 ack메세지를 보낸다.
3. 1,2번이 조건이 만족이 안되면 계속 메세지를 안 보낼 수는 없으니 Pi의 로컬 업데이트 메시지가 수행이 된 다음에 Pj가 보낸 메시지에 대해서 동의해 줄 수 있음
이처럼 logical clock개념만으론 부족하니 ID를 이용해서 이벤트가 발생한 순서를 지정을 하자. 메세지안에 logical clock값은 보낼 때의 logical clock값이 아니라 보내기 전 해당 이벤트가 발생할 당시에 logical clock값을 메시지의 timestamp에 담는다.


만약에 P2가 샌프란시스코 메시지의 m보다 내가만든 local 메세지 n을 먼저 받으면 n에 대해서는 여전히 ack메세지를 보내느냐? yes. 왜냐하면 나의 메세지이기 때문에. 그런데 내가 ack메세지를 보낸뒤에 나보다 우선순위가 높은 메세지가 오게 될경우에 내가보낸 ack은 어떻게 될까? 여기선 우선순위를 따질필요없이 내꺼랑만 비교를 하면 된다. 다시말해 n을 보낸 직후에 m이 온다면 문제가 없는걸까? 문제없음. NY가 자신의 메세지가 나중에 올수도 있다는 사실을 알 필요가 없다. 어처피 ack메세지를 다 보내지 않을것이다. 앞에서 막는놈이 있음.

정리하자면 P1과 P2는 각자의 업데이트 메세지 m과 n을 날린 상황이고 SF와 NY는 m에 대해서 ack을 받는다. 모두가 ack메시지를 보냈기 때문에 m은 실행할 수 있다. 그래서 m은 queue에서 빠지고 애플리케이션으로 전달이 될것이다.(실행) 그래서 그다음에 양쪽에 m에대한 수행을 한다.(잔액에 100달러 더하기) 그래서 양쪽 모두 1100 달러가 된다. 그 후에 SF는 자기의 메세지인 m을 처리를 완료했기 때문에 세번쨰 조건에 따라서 n에대한 ack을 보내줄수 있다. 그래서 n에 대해서 ack메세지를 모두 받았기 때문에 n의 수행을 할 수 있다. 이러한 과정으로 SF와 NY이 추가적인 대화 없이 받는 메시지만 가지고 동일한 순서로 오퍼레이션을 수행할 수 있게 된다.
그럼 서울이라는 P3이 추가된다면 totally ordered 멀티캐스팅이 가능할까? P3의 ID를 3이라고 하자.

Logical clock : Vector clocks
lamport의 logical clock에서 문제점이 있었다. 서로 다른 컴퓨터에서 a라는 이벤트와 b라는 이벤트가 발생할 때 어떤 이벤트가 먼저 발생했는지 알기 위해서 a와 b의 logical clock값인 C(a)와 C(b)의 값을 비교한다고 누가 먼저 발생했는지 알 수가 없었다. 그래서 lamport의 logical clock에서는 causality(인과관계)를 알 수가 없다는 문제점이 있었다.

Vector clock : 내 컴퓨터의 logical clock값만 가지고 있는 것이 아니라 다른 컴퓨터에서 가지고 있는 logical clock값을 계속 유지를 하겠다는 뜻. a에 관한 vector clock값은 VC(a)라고 표시한다. VC(a) < VC(b)라고 한다면 a가 b보다 먼저 발상한 이벤트라는 것을 보장해 준다. Pi는 VCi라는 벡터값을 유지를 하게 된다. 만약 프로세스가 3개라면 vector clock값은 3개(참여하는 프로세스의 개수)가 된다.
vector clock 알고리즘
1. lamport의 logical clock이 업데이트되는 알고리즘과 거의 똑같다. 어떤 이벤트가 발생했다면 이벤트가 실행되기 전에 해당 vector clock값을 하나 증가시키자.
2. Pi가 Pj에게 m이라는 메시지를 보낸다면 logical clock에서는 m이라는 메세지안에 timestamp를 담아서 보냈었다. vector clock에서는 내가 알고 있는 vector clock을 모두 메세지안에 넣어서 다른 프로세스에게 보낸다.
3. 메시지를 받았으면 내가 갖고 있는 vector clock값과 메세지에 담겨 있는 timestamp상의 vector clock값을 비교를 한다. 그래서 max값을 취한다.(큰놈으로 업데이트를 한다는 뜻) 업데이트를 하고 메세지를 받았으니까 이벤트의 logical clock값을 1 증가시킨다.
만약 이벤트 a의 timestamp인 ts(a)가 i번째 clock값에 -1을 한 것을 Pi가 a의 앞서서 몇 번의 이벤트를 발생했었는지를 나타낸다. 메세지를 받았다면 그 안에 있는 timestamp안에 vector clock값들이 의미하는 것은 메세지를 받았다는 이벤트 전에 이미 다른 애들이 몇번의 이벤트가 발생했는지를 알겠다는 것이다.
vector clock을 이용해서 causal communication을 강제로 수행할 수 있다. 즉, 어떤 메시지가 수신이 됐을 때 처리가 되려면 애플리케이션으로 전달이 되어야 실행이 됐었는데 causal communication은 무조건 전달이 되는 것이 아니라 만약 내가 이 이벤트에 앞선 이벤트가 있다면 그 이벤트를 받지 못했을 경우에 기다렸다가 전달을 해준다는 것이다. 다시 말해 원인과 결과관계가 있는 메시지들이 있을 경우에는 바로 애플리케이션으로 전달이 되는 것이 아니라 기다려주겠다는 것이다.
causal communication을 강제하는 예제에서는 가정해야 할 사항이 있다.
모든 이벤트들에 관한 logical clock값을 업데이트하는 게 아니라 메시지를 주고 받는 이벤트에 한에서만 logical clock값을 업데이트 한다. 어떤 메세지를 보낼때 보내는 프로세스는 자신의 vector clock값을 1 증가시킨다. 또한 메세지가 timestamp를 갖고 있을때 수신한 프로세스의 clock값과 메세지에 담겨있는 clock값을 비교해서 더 큰 인덱스로 업데이트만 한다.(기존에 vector clock에서는 메세지를 받고 난 뒤에 받은 거에 +1을 했지만 여기선 안 함)
그래서 두 가지 조건이 만족이 되면 애플리케이션으로 전달이 될 것이다.
1. ts(m)[i] = VCj [i] + 1 이게 뭔 말이냐면 P0 [2 1 0]이고 P1 [1 1 2]라면 P1은 P0이 지금까지 이벤트가 1번 발생한 거로 알고 있는데 내가 받은 메시지의 timestamp의 값이 2 1 0이면 1+1 =2가 성립이 되어서 P1은 P0이 다음으로 보낸 메시지를 내가 받은것이라고 확인할 수 있다. 만약 P1 [0 1 2]라면 P1은 1에 해당하는 메세지를 받지 못한 상태라는 걸 알 수 있다. 즉 이 조건은 보내는 놈의 time logical clock값을 확인하는 거다
2. ts(m)[k] <= VCj [k] for all k!= i 이 조건은 보내는 놈의 time logcial clock값을 확인하고 그 외에 다른 logical clock값도 확인하겠다는 것이다. 받은 놈이 알고 있는 다른 프로세스의 logical clock값보다 받은 메세지안에 담겨있는 timestamp안에 담겨 있는 logical clock값이 더 크거나 같으면 된다. 다시 말해 내가 알고 있는 logical clock값이 timestamp에 담겨있는 logical clock값보다 크거나 같다는 것은 내가 적어도 메시지에 담겨있는 이벤트보다는 더 많이 받았다는 것이다. 만약에 timestamp안에 담겨있는 다른 logcial clock값보다 내가 알고 있는 logical clock값이 더 작으면 다른 놈이 보낸 메시지를 내가 받지 못했다는 것이다. 즉, 메세지를 보낸놈 말고도 다른놈이 메세지를 보냈는데 그거를 내가 못 받았다는것을 확인하는것이다.
정리하자면 1번은 이 메시지를 보낸 놈이 이 메세지전에 다른 메세지를 보냈는데 그걸 내가 받았는지 못받았는지 확인하는거고 2번은 보낸놈 말고 다른 프로세스가 보낸 메시지는 내가 이미 받은 상황인지 아닌지를 확인하는 것이다.
예제를 통해서 살펴보자

vector clock에서 고려해야 할 사항들
미들웨어 시스템 중에 ISIS와 Horus라는 것이 있었는데 얘들 totally-ordered, causally-ordered 기능을 지원을 해줬었다.
이 기능을 미들웨어에 넣어서 하는 게 맞을지 애플리케이션에 넣는 게 맞을지 논쟁이 있었다. 만약 미들웨어가 이 역할을 다 한다면 애플리케이션이 받는 메세지안에 실제 내용을 까보지 않을 거고 까본다 하더라도 애플리케이션이 아닌 이상 그 의미를 알지 못한다. 그렇기 때문에 미들웨어가 메시지들 간에 causuality가 존재하는지 확인이 불가능하다.
그래서 애플리케이션이 다 처리하도록 하자.
end to end라는 개념이 있다. 서비스라는 것을 말단 레벨(애플리케이션)에서 처리하는 것이 맞다고 주장하는 것이다. 단점으로는 애플리케이션에서 위에서 했던 모든 내용들을 다 구현해야 한다. ordering이 애플리케이션에서 큰 비중을 차지하지 않는다면 미들웨어에서 제공하는 것이 좋다.
싱글 프로세스에서 발생했던 mutual exclusion문제를 분산시스템에서도 발생하니 해결해야 한다.
mutual exclustion : 여러 개의 프로세스가 동시에 하나의 공유리소스를 액세스 하려고 할 때 충돌문제가 발생할 수 있다.
분산시스템에서는 여러 대의 컴퓨터들이 하나의 리소스에 액세스 할 때 문제가 발생한다. 싱글프로세스에서는 locking 메커니즘을 사용해서 예방했었다.
분산시스템에서 리소스를 동시에 요청하면 줄을 세워서 한 번에 하나씩 액세스 할 수 있는 메커니즘이 필요하다.
Token-based solution과 Permission-based solution이 있다.
token-based solution은 빙글빙글 돌고 있는 토큰이 있는데 이 토큰을 가진애만 허가권을 갖게 된다. 즉, 공유리소스를 사용하고자 하는 프로세스가 있다면 그 프로세스는 아무 때나 액세스 할 수 없고 토큰이 있을 때만 가능하다. 다 썼으면 다른 애가 쓸 수 있도록 토큰을 다시 반납하자.(다른 애들도 쓰도록)
장점 : starvation을 피할 수 있다. 공유리소스를 사용하는 프로세스가 있다면 언젠가 허가를 받을 수 있음, beadlock 피할 수 있다.
단점 : 토큰이 없어질 경우 골치 아파짐. ex) 토큰을 기다리는 프로세스가 있다면 누가 토큰을 갖고 있는지 토큰이 없어졌는지 알 방법이 없다. 그렇기 때문에 recovery 메커니즘이 필요하다. 그러나 간단하지 않다.
permission-based solution은 3가지로 나눠져서 허가를 받자. 허가를 받은 애만 액세스 할 수 있음
1. centrailized algorithm : 대장프로세스에게 물어봐서 허가를 할지 안 할지 알려줌
2. decentralized algorithm : 대장이 없고 민주적으로 참여한 모든 프로세스에게 다 물어봐서 허가를 많이 받은 애가 최종허가를 받음
3. distributed algorithm : 경쟁자 프로세스들끼리 경쟁(합의)해서 이긴 애가 허가를 받자.
크게 4가지 방법 중에서 가장 단순하고 튼튼하며 활용도가 높은 것이 아래에 나오는 centralized 알고리즘이다.

장점 : 간단해서 구현하기 좋다. 요청메시지 ok메시지 release메시지 3개만 있으면 가능하다.
단점 : 대장 놈이 죽으면 모든 서비스가 먹통이 된다.
그러나 단점대비 장점이 좋아서 많이 활용된다.
이러한 단점을 보완하기 위해서 나온 것이 decentralized 알고리즘이다.
decentralized 방식은 가정이 있음
액세스하려고 하는 각각의 리소스가 복제되었다고 가정하자. 각각의 replica들은 이 replica들을 관리하는 코디네이터(서버)가 있다. 그래서 하나의 프로세스가 리소스를 하고싶으면 n개의 모든 코디네이터들에게 물어본다. 그래서 투표를해서 허가를 과반수 이상 받게 되면 그 프로세스는 리소스를 엑세스 할 수 있게 된다. single pointer of failure문제는 해결이 되었다. 코디네이터가 n개이기 때문에 하나가 고장나더라도 다른 코디네이터를 이용해서 계속 작동이 가능하다. 만약 코디네이터가 죽고난 뒤에 다시 살아나면 그전에 살아있던 코디네이터가 응답했었던 내용들이 사라질 수 있는 문제점이 있다.(내가 예전에 허락을 해줬는지 안해줬는지 기억이 다 사라짐)
단점 : 만약 많은 노드들이 같은 리소스에 대해서 엑세스 한다면 문제가 생긴다. 만약 10개의 노드들이 하나의 리소스에 대해서 액세스를 한다면 모든 노드들이 n등분이 되어서 과반수의 득표를 하지 못하는 문제점이 발생할 수 있다. 그럼 모든 프로세스들이 엑세스를 하지 못하는 경우가 발생할 수 있다.
그래서 나오게 된 것이 distributed 알고리즘이다.
Lin's의 알고리즘(decentralized 알고리즘)의 경우에 아무도 리소스에 대한 권한을 얻지 못하게 되는 경우가 생길 수 있다.
이 알고리즘도 액세스 할 가능성이 있는 프로세스들 사이에서만 합의하에 한 프로세스가 리소스를 액세스 하는 방식이다. decentralized와는 다르게 확률적인 것이 아니고 deterministic 한 mutual exclusion algorithm으로 구성이 되었다. 이 알고리즘을 동작하기 위해서는 프로세스들끼리 주고받는 모든 메시지들은 total-ordering이 되어야만 한다.

리퀘스트 메시지를 받았을 때에 ok를 보낼지 말지에 관한 판단기준이 3가지가 있다.
1. 요청 메시지를 받았을때 그 메세지가 내가 원하는 리소스인지 혹은 내가 갖고 있는 리소스인지 확인한다. 내가 갖고있는것도 아니고 원하는것도 아니라면 ok를 보낸다.
2. 요청 메세지를 받았는데 내가 이미 그 리소스를 사용 중이라면 따로 ok를 보내지 않고 queue에 저장을 한다. 리소스를 다 사용하고 난 뒤에 ok메시지를 보내주기 위해서.
3. 내가 리소스를 액세스 하고 있지는 않지만 나와 다른 프로세스가 액세스를 원하는 경우에는 서로 간의 timestamp를 비교를 해서 timestamp값이 작은 프로세스가 우선순위가 더 높아서 이긴다.(ok를 보내지 않고 queue에 요청메시지 정보를 저장한다.)
이러한 알고리즘은 deadlock이나 starvation 같은 문제없이 mutual exclusion을 보장해 주는 알고리즘이다.
서버를 사용하지 않으니 single point of failure가 발생하지 않는 장점이 있다.
단점으로 어떤 프로세스가 고장이 나서 내가 요청메시지를 보냈는데 응답이 오지않는 상황이 발생 할 수 있다. 메세지를 보낸 프로세스의 입장에서는 거부해서 안오는건지 프로세스가 고장이 난건지 구분할 수 가 없는 문제가 발생한다. 그래서 요청메세지를 받은 노드들은 ok가 아닌경우에 거부메세지도 보내는것이 확실하게 돌아가는 알고리즘이 될것이다. 또한 서로간의 합의하에 돌아가는거기 때문에 각 프로세스에 대한 멤버쉽 정보를 유지하고 있어야한다. 혹은 multicast를 이용해서 요청메세지를 보내고 받는 수단이 필요하다. 또한 이러한 알고리즘은 요청메세지를 여러 개 보내고 받아야 해서 느리다는 단점도 있다. 그래서 centralized방식에 비해서 느리고 복잡하고 비용도 들고 탄탄하지도 않다.
결과적으론 centralized방식이 더 낫다.
mutual exclustion : A token ring algorithm
A token ring algorithm : 토큰기반 알고리즘으로 허가를 받는 것 대신에 토큰을 이용한다. 리소스를 원하는 프로세스는 따로 요청을 하지 않고 토큰이 와서 갖게 되면 액세스 권한을 받는다. 토큰이 없는 프로세스들은 기다려야 한다. 토큰이 프로세스들 사이를 이동해야하기 때문에 ring형태의 logical 하게 구성되어 있다.

토큰 링의 알고리즘
링으로 구성된 프로세스사이에 룰이 필요한데, 최초의 0번 프로세스(ID가 가장 작은 프로세스)가 처음 토큰을 갖게 된다. 만약 아무도 리소스를 원하지 않으면 토큰은 계속 돌아간다.
그러나 이러한 알고리즘도 문제가 있다. 토큰이 없어졌을 때가 문제이다. 어떤 프로세스가 토큰을 기다리고 있는데 토큰이 계속 오지 않는 상황이 발생했을 경우에 누가 리소스를 쓰고 있는중인지 아니면 토큰이 없어졌는지 알 수가 없다. 토큰이 없어진 줄 알고 하나를 만들었는데 만약 누가 리소스를 쓰는 중이었다면 링에 두 개의 토큰이 생기는 상황이 되어서 mutual exclution조건이 깨져버린다. 또한 중간에 프로세스가 고장 나면 문제가 발생할 수 있다. 그러나 회복은 쉽다. 내가 토큰을 갖고 있다가 옆에 프로세스에 토큰을 넘겼는데 옆에 프로세스가 죽은 경우에 문제가 발생한다. 이 문제를 해결하기 위해 ack메시지가 필요하다. 다음 프로세스에게 토큰을 보내고 토큰을 받은 프로세스는 잘 받았다고 ack메시지를 보낸다. 그 ack메시지를 받으면 잘 받았구나라고 알 수 있고 ack을 받지 못하면 고장 났다고 인지해서 그다음 프로세스에게 토큰을 보내면 된다. 그럼 나는 그다음 프로세스에 대한 정보를 알고 있어야 한다. 이러한 과정으로 인해 내가 모든 프로세스에 관한 정보를 알아야 할 문제가 생길 수가 있다.
지금까지 mutual exclustion알고리즘 4가지를 살펴보았다. 이제 centralized, decentralized, distributed, toke ring알고리즘을 비교해 보자. 결론부터 말하면 centralized가 제일 좋다. deceatralized인 경우에 서버가 없어서 n개의 코디네이터들에게 메시지를 보내고 받아야 한다. 그중에서 과반득표를 못하면 여러 번 다시 시도해야 하는 상황이 발생한다. decentralized 이외에 다른 모든 알고리즘들은 프로세스가 고장 나면 문제가 발생할 수 있다. 나머지는 오히려 centralized의 단점을 보완하기 위해 출시됐는데 오히려 고장이 나면 single point of failure문제는 아니지만, 여전히 문제가 발생할 수 있다. decentralized는 프로세스가 고장 나더라도 나머지 코디네이터들끼리 동작을 하면 되자만 과반수를 못 받을 경우에 starvation문제가 발생할 수 있다.

Election algorithms : 서버가 없는 P2P구조에서 하나의 노드가 서버의 역할을 해야 할 경우가 있다. 여기 노드들 사이에서 합의하에 누가 코디네이터가 할 건지 결정하는 방식. 룰은 프로세스 number가 가장 큰 프로세스가 코디네이터가 되자.
일단 이 알고리즘도 가정이 필요하다.
프로세스는 다른 모든 프로세스의 프로세스 number를 알고 있어야 한다. 그런데 프로세스들이 넘버가 가장 큰 애를 코디네이터로 정하자는 것은 알지만 현재 P2P에 누가 들어와 있는지, 누가 가장 큰지 확인하는 방법이 필요하다.
그러한 방법으로 1982년에 나온 bully alogrithms이 있다. 기존에 이미 코디네이터가 있다고 가정하고 중간에 다른 프로세스가 코디네이터가 동작하지 않는다는 것을 안다고 가정하고 시작하자. 예를 들어 P가 코디네이터가 동작하지 않아서 새로운 코디네이터가 필요하다는 것을 안다고 가정하면 P는 새로운 election 시작한다. 그래서 election(투표) 메시지를 P보다 높은 프로세스 number를 갖고 있는 프로세스에게만 election메시지를 보낸다. 왜냐하면 나보다 넘버가 작으면 코디네이터가 될 수 없기 때문이다. 만약 election메세지에대한 응답이 안왔다면 내가 제일 number가 큰 프로세스니까 내가 코디네이터라고 판단한다. 만약 응답을 했을 경우엔 나보다 넘버가 큰 프로세스들이 있다는 것이니 이중에서 코디네이터가 결정이 될것이니 기다리면 된다. 혹은어느순간 프로세스가 나보다 낮은 애로부터 election메세지를 받을 수도 있을 것이다. 그럼 받은 프로세스는 ok를 하고 내가 이제 election을 주도한다. 그래서 나도 나보다 큰 프로세스에게 전송한다. 그래서 결과적으로 모든 프로세스 중에서 하나만 election에 남게 된다. 그래서 그 프로세스만 코디네이터가 된다. 코디네이터로 결정된 프로세스는 내가 새로운 코디네이터라고 다른 프로세스들에게 알려줘야 한다.


bully algorithms과 비슷한 알고리즘으로 ring algorithm이 있다.
ring algorithm : 프로세스들이 logical 하게 링형태로 이어져있다. 그래서 각 프로세스는 나의 succ정보를 알고 있다. 만약 현재 코디네이터가 동작하지 않는다는 것을 판단하게 되면 그 프로세스는 election을 새로 시작한다. 그래서 election메시지를 새로 만들어서 나의 succ에게 election메세지안에 내 프로세스 번호를 넣어서 보낸다. 그래서 이러한 과정으로 election메세지 안에 프로세스 번호가 계속 추가가 될것이다. 만약 succ가 off상태면 건너뛰고 그 다음 노드에게 보낸다. 그래서 링한 바퀴를 돌면 결국 원래프로세스에게 돌아올 것이다. 그안에는 모든 프로세스 번호가 다 들어있기 때문에 거기서 번호가 가장큰 프로세스를 코디네이터로 결정하고 이 프로세스가 새로운 코디네이터라고 메세지를 다 보낸다. 그렇게 총 두 바퀴 돌면 누가 새로운 코디네이터인지 알게 된다.

그러나 이러한 링 알고즘방식의 문제점은 election 메시지에 노드를 거쳐갈 때마다 프로세스 ID가 하나씩 붙게 되어서 메시지가 커지게 되는 문제점이 있다. 이것을 개선하기 위해서 election메시지에 ID를 추가하지 말고 비교해서 큰 ID만 남겨놓는다. 그러면 최종 ID만 남아서 새로운 코디네이터라고 정하면 된다.
'Computer Science > 분산시스템' 카테고리의 다른 글
| [분산 시스템] Consistency and Replication (0) | 2024.06.10 |
|---|---|
| [분산 시스템] Naming (0) | 2024.05.12 |
| [분산 시스템] Communication (0) | 2024.04.15 |
| [분산 시스템] Process (0) | 2024.04.05 |
| [분산 시스템] Architectures (0) | 2024.03.31 |