프로세스가 실행되려면 하나의 스레드는 무조건 있어야 함
프로세스란 실행 중인 프로그램
lock machanism : 스레드가 메모리 공간을 사용할 때 다른 스레드들은 사용하지 못하도록 잠가서 충돌을 방지하는 것
분산시스템에서 스레드를 사용하는 이유? 프로세스 안에서 concurrency 한 task를 수행하기 위해서
- Single-threaded process
프로세스의 퍼포먼스가 떨어질 수 있음
동시에 수행해야 할 것이 많은데 중간에 하나의 태스크가 오래 걸리면 다음 태스크를 수행하기까지 오래 걸림
blocking system call : 프로세스가 함수를 호출하고 그 함수가 주어진 역할을 한 뒤에 리턴이 될 때까지 프로세스는 블록 상태가 되는 것
- Multi-threaded process
퍼포먼스를 향상할 수 있음
스레드를 분리해서 계산을 하는 동시에 화면에 출력
분산시스템에서 스레드의 역할
다중스레드를 이용해서 blocking system call을 이용할 수 있게 해 줌 but 전체 프로세스는 blocking 시키지 않음.(concurrent tasks)
다중스레드를 이용해서 퍼포먼스를 향상할 수 있음.
clinet 측면에서 다중 스레드
1. communication latency를 줄여줄 수 있다. 즉, 딜레이를 줄여줌(ex web browser)
2. 커넥션을 여래개 맺어서 퍼포먼스를 향상해 줌
server 측면에서 다중 스레드
파일서버를 다중 스레드로 만들자
dispatcher 스레드 : 클라이언트의 요청을 받아들이는 역할
worker 스레드 : 사용자의 요청을 직접 수행하는 역할

파일 서버가 스레드가 하나라면? 스레드가 하나밖에 없기 때문에 작업 시간이 오래 걸리는 task가 있다면 그 task가 끝날 때까지 기다려야 하므로 delay가 걸림
그럼 스레드 하나로 할 수 있는 방법이 없을까? 있음, blocking system call을 사용하지 않으면 됨
non-blocking system call(함수를 호출하면서 태스크를 요청하는데 태스크가 끝날때까지 기다리지않고 바로 리턴함)을 이용하자. 그대신 파일 오퍼레이션의 상태를 계속 확인해야됨(즉, 완료가 되지않은 테스크가 있을 수 있으니 확인을 해야 된다)
non-blocking system call : 테이터를 읽어줘라고 요청하고 읽을 수 있는지 try 해보는 것(읽을 수 있으면 바로 리턴, 읽을 수 없으면 못 읽은 채로 바로 리턴 받음)
asynchronous system call : 요청을 해두고 바로 리턴을 받는 것( 따로 백그라운드로 요청을 해놓는 것)
| model | 특징 |
| Threads | Parallelism, blocking system calls |
| Single-threaded process | No parallelism, blocking system calls |
| Finite-state machine | Parallelism(눈으로보기에 동시에 보이는것 처럼 보임), non-blocking system calls |
스레드가 많더라도 무조건 좋은 것은 아님. 그에 따른 오버헤드가 필요해서 관리가 어려움
가상화(Virtualization)
cpu는 하나지만 동시에 실행이 되는 거처럼 보이도록 하는 것, 다른 시스템을 흉내 내서 프로세스를 실행시켜 주는 환경
가상화의 두 가지 형태
- Process virtual machine
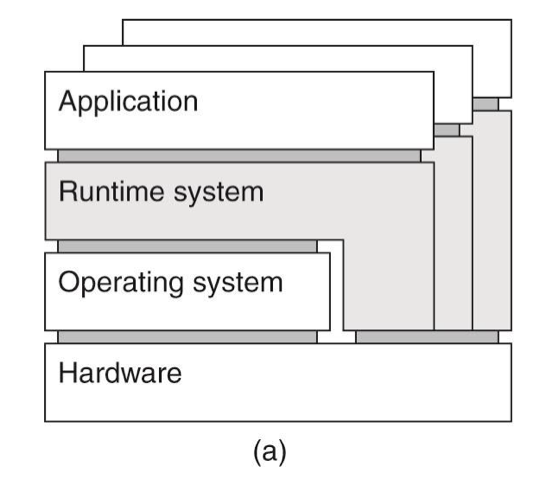
다른 os의 동작을 흉내 내는 App
ex) java 가상머신
- Virtual machine monitor

가상머신 모니터가 전체 하트웨어를 직접 제어 os부터 app까지 실행 가능
상대적으로 process virtual machine보다 성능이 좋음, 보안측면에서도 좋을 수 있음(해킹에 걸릴 경우 그 부분만 제거하면 됨), portability측면에서도 좋음(내가 사용했던 환경을 다른 하드웨어로 옮길 수 있음)
ex) VMware
Client - Networked user interfaces
클라이언트가 서버와 사용자의 상호작용(interaction)을 하도록 해줌
두 가지 상호작용 방법


Clients-side SW for distribution transparency
클라이언트 쪽 소프트웨어는 단순히 UI만 제공하는 것이 아니고 UI이상의 역할을 한다. 자체적으로 프로세싱을 하고 데이터를 관리하기도 한다.
Distribution transparency : 사용자 입장에서 로컬에서 쓰는 거처럼 이용이 가능
access transparency : 데이터가 heterogenous 하더라도 동일한 방식으로 이용이 가능
location, migration, relocation, replication transparency : 이 4가지 측면에서 변화가 생긴다면 미들웨어가 숨겨주는 역할을 함
failure transparency : 미들웨어가 연결이 실패했다는 사실을 가능한 숨김
concurrency, persistency transparency : 이런 것들은 퍼포먼스 때문에 클라이언트보다 서버 쪽에서 제공해 줌
클라이언트 쪽 프로세스는 사용자 편의를 좀 더 신경 씀, 서버는 퍼포먼스 쪽을 좀 더 신경 씀
Server
- Iterative server : 서버 프로세스가 스레드가 하나뿐이어서 순차적으로 하는 것
- Concurrent server : 다중스레드를 사용해서 concurrent 하게 task 수행이 가능
클라이언트는 어떻게 서비스의 end point(port)를 알게 될까?
1. 표준 포트번호 ex) FTP(21), HTTP(80)
포트번호가 바뀌는 경우에는?

서버머신에 별도의 Daemon 프로세스(포트번호 관리 서비스)를 만들어서 일반 프로세스가 사용하는 포트정보를 Daemon에 연결하여 관리
1. 클라이언트 측은 내가 사용할 포트번호를 서버 쪽에 먼저 물어봄
2. 서버가 클라이언트에게 포트를 제공
그런데 이 방법은 비효율적임. 서버가 계속 돌고 있어야 하기 때문에 리소스가 낭비가 될 수 있음
해결방법 : 클라이언트가 요청할 때만 서버를 돌리기

이와 같은 방법으로 필요한 요청이 들어올 때만 서버가 돌아가기 때문에 리소스 낭비를 줄일 수 있다
1. 클라이언트가 포트번호를 모르는 채로 무조건 슈퍼서버에게 요청을 한다.
2. actual서버가 서비스를 제공
클라이언트가 서비스를 중간에 취소하고 싶을 때 방법
1. 클라이언트와 서버의 연결을 강제로 끊어라(simple)
2. out-od-band data 사용
서버의 구성
- stateless server : 클라이언트의 상태정보를 저장하지 않는 서버
장점 : 서버의 상태가 변경이 됐을 때 이 변경된 사항이 클라이언트에게 큰 영향을 미치지 않는다.
단점 : 클라이언트가 쓰기, 읽기 요청을 할 때마다 파일의 open과 close를 매번 해야 한다.(클라이언트의 상태정보를 저장할 수 없기 때문)
- stateless with soft state : 클라이언트의 상태정보를 일정 시간 동안만 저장하는 서버
정해진 시간 동안에만 클라이언트의 정보가 의미가 있을 경우에 사용하면 좋다. 서버가 자신의 상태 정보를 바꾸면 그 사실을 클라이언트에게 직접 통지를 해주는데 일정시간이 끝난 뒤에는 알려주지 않음
- statefull server : 클라이언트의 상태정보를 저장해서 서비스를 효율적으로 전달해 주는 서버
장점 : 클라이언트가 요청하는 것이 있으면 그 퍼포먼스가 향상된다. (하나의 파일에 대해서 지속적으로 write, read 할 경우에 stateful서버가 stateless서버 보다 퍼포먼스가 좋음. 왜냐하면 클라이언트가 요청한 파일의 상태를 오픈한 채로 둘 수 있기 때문)
단점 : 서버의 상태가 변경이 됐을 때 이 변경된 사항이 클라이언트에게 영향이 갈 수 있어서 관리하기 복잡하다. 또한 만약에 서버가 crash가 나면 나중에 복구할 때 까다로워질 수가 있음(클라이언트의 상태정보가 사라졌기 때문에 클라이언트가 어디까지 작업을 했는지 사라져서 이것을 방지하기 위해 관련 정보를 백업을 해야 함)
server cluster : 서버 머신들이 여러 개가 있는데 이것들이 cluster(여러 개 서버를 로컬 네트워크로 연결)로 구성되어 있음.

-서버 클러스터를 구성할 때 주의할 점-
1. 서버클러스터가 여러 개 있다는 사실을 숨기자, 그래서 동일한 방법으로 request/reply를 받을 수 있도록 하자.
2. 서비스종류가 다르더라도 동일한 access포인트를 제공해 주자 즉, 서버는 사용가능한 액세스 포인트는 여러개 두지만(클라이언트에게는 숨김) 클라이언트에게는 하나의 엑세스 포인트를 제공해 주자.(그냥 single access포인터만 사용하게 될 경우 그 포인터가 고장 나면 전체 서버가 마비될 가능성이 있기 때문에)
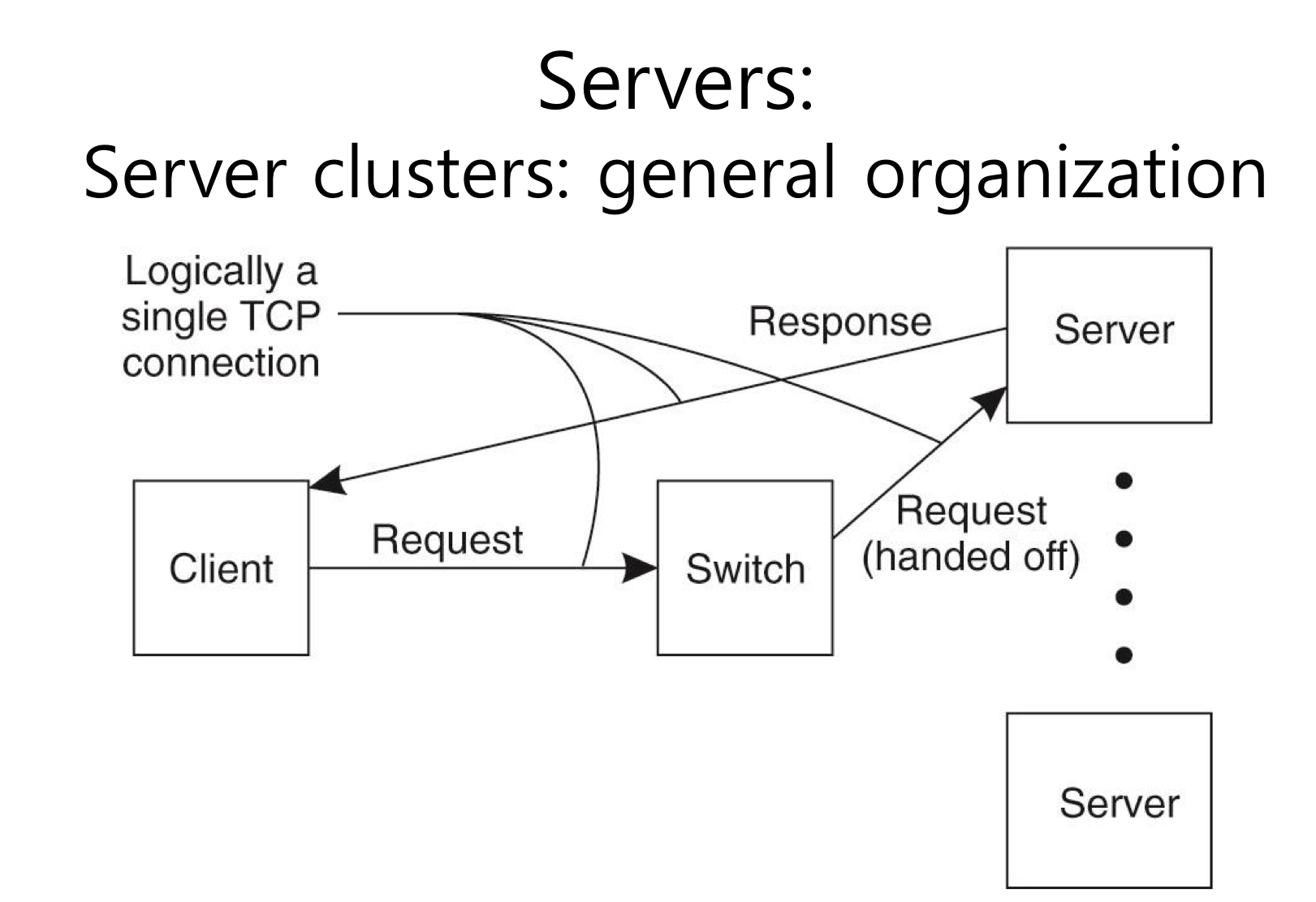
server cluster : distributed servers
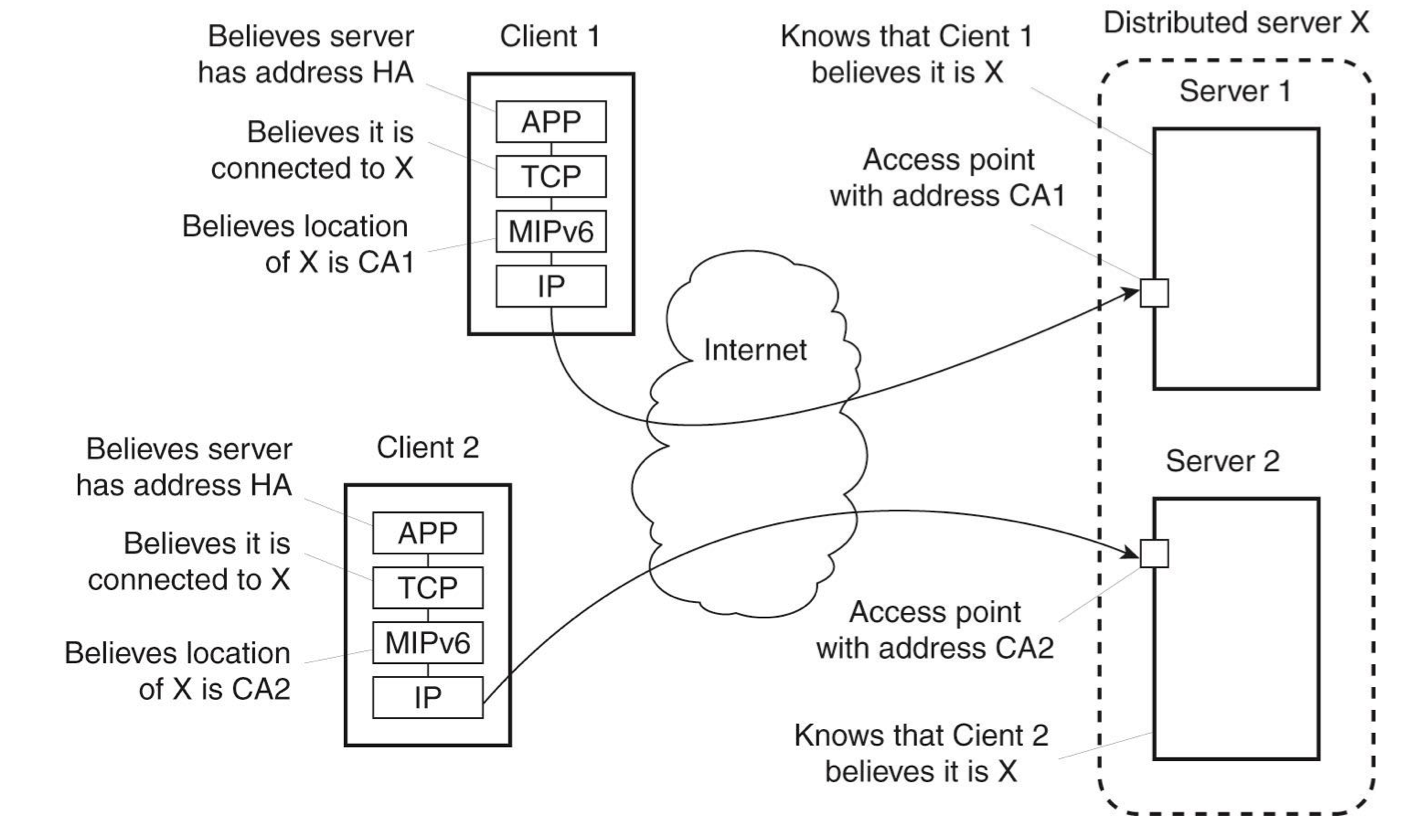
ex) MIPv6 : 하나의 모바일 노드는 Home address(Hoa)를 가지고 있음, 그 노드는 mobile이기 때문에 Hoa를 벗어서 나서 움직일 수 있음, 그러나 사용자 입장에서는 주소가 바뀐 것을 알고 싶지 않고 그냥 원래의 HoA에 연결을 함. 그래서 HoA에 있는 home agent가 바뀐 주소(care-of address)(CoA)를 얻어서 바뀐 주소로 바로 연결을 시켜주는 방식
stable access point in distributed servers
-MIPv6을 사용
- 외부에서 보기에 stable 한 address(Contact address) 할당
- 서버들 중에 하나가 access point의 역할을 수행을 한다. 이렇게 하기 위해서 access point역할을 하는 서버가 자신의 주소를 home agent에 등록을 한다.
- 모든 트래픽은 homeagent를 거쳐서 access point역할을 하는 서버로 간다.
- access point역할을 하는 서버가 고장 나도 다른 서버를 다시 등록을 하면 된다.
하지만 위의 조건도 문제점이 발생한다.
home agent를 거쳐서 access point역할을 하는 서버가 모든 트래픽을 받기 때문에 bottleneck현상이 발생한다.
해결책
1. 그냥 바뀐 주소를 클라이언트에게 알려주자(그러면 부담을 덜게 할 수 있음), 근데 원래 모르게 하기 위해서 이 기법을 쓰는 거 아닌가? 그래서 주소값을 애필리케이션이 알고 있는 게 아니고 미들웨어 쪽에서 알도록 함
2. access point의 역할을 한 명이 하는 것이 아닌 여러 명이서 하도록 하자.(단, 클라이언트 쪽에서 contact address는 그대로 사용)
서버클러스터들을 관리하는 방법
1. 관리자가 원격에서 서버를 관리하기(각각의 서버 노드에 연결을 해야 하니 어려움)
2. 관리자가 사용하는 관리전용 머신을 사용
어쨌든 서버의 개수가 많아질수록 서버관리하기 어려움
Code(Process) migration
Code migration 하는 이유? 성능 향상을 위해서
ex) 어떤 머신을 돌리는데 부화가 너무 자주 걸려서 놀고 있는 머신에 옮겨서 퍼포먼스를 향상하자.

Code migration의 모델들
- Code segment : 코드 파트
- Resource segment : 리소스 파트(ex. 파일, 프린터)
- Execution segment : 실행 파트(실행하는데 필요한 상태정보들)
mobility models : Weak vs Strong mobility
- weak mobility는 코드파트만 이동 ex) java applets
- strong mobility는 코드파트와 실행파트를 이동, 더 일반적인 접근이지만 구현하기 어려움
mobility migration을 보내는 쪽에서 시작을 시키는건지 받는쪽에서 시작하는건지 나눌수있음
- sender-initiated mobility : migration이 보내는쪽에서 시작을 한다는 뜻(ex. 프로그램을 서버 쪽으로 보내는 것)
- receiver-initiated mobility : 웹브라우저가 필요에 의해서 서버로부터 코드를 받는 것
receiver 쪽이 sender보다 간단한 측면이 있다. 왜냐하면 receiver 쪽에서는 anonymously(익명)하게 받을 수 있는 부분이 많음. 그러나 업로드 같은 경우에는 내가 누군지 밝혀야 하는 부분이 많고 인증절차도 신경을 써야 함.
weak mobility의 다른 타입들
타깃 프로세스에 의해 실행될 때 : 별도의 프로세스를 생성할 필요가없음, 그러나 보안쪽에 문제가 발생함
분리된 프로세스에 의해 실행될때 : 위에 있는 보안문제를 해결해 줌
strong mobility의 다른 타입들
실행 중 인프로세스를 옮길 때, 복사할 때

리소스 migration
코드 파트처럼 이동할 수 있으면 좋을 텐데 리소스는 그렇지 못함
그럼 어떻게 쓰지?
리소스를 옮기지 못하고 프로세스는 옮겼다면 원격으로 그 리소스를 사용하자.(ex. global URL)
리소스 종류 중에 같은 종류의 리소스가 있다면 그 리소스를 사용하자
Three types of process-to-resource binding
- Binding by identifier : ID를 가지고 리소스를 액세스 하는 경우에 아이디를 갖는 리소스만 사용가능함
- Binding by value : 리소스의 종류가 여러 개가 있는데, 아이디는 다르더라도 value가 갑았다면 사용할 수 있는 리소스
- Binding by type : value보다 더 느슨함, 프로세스가 사용하는 리소스가 파일타입이라면 value가 다르더라도 파일 타입이라면 리소스를 사용가능함
Three types of resource-to-machine binding
- Unattached resources : 머신에 종속적이지 않은 리소스, 즉, 다른 머신으로도 이동이 쉬움 ex) data files
- Fastened resources : 종속적이지 않아서 다른 머신으로 실질적으로 이동은 가능하나, 이동을 하기 위해서 cost가 많이듬 ex) wrb site전체, 로컬 데이터베이스
- Fixed resources : 하드웨어에 종혹된 리소스, 이동이 불가능함

리소스가 프로세스에 identifier로 바인딩되고
- 또한 그 리소스가 unattached라면 : ID를 가지고 그 리소스가 이동이 자유로움 ex) URL, 만약에 리소스가 다른 곳에서 같이 사용 중이라면 이동시키기 어렵다. 그럴 땐 global referenece(현재 머신에 있는 리소스에 액세스 할 수 있는 reference를 두는 것)를 만들자
- 또한 그 리소스가 Fastened of fixed라면 : 공유가 되든 안되든 이동하기가 실질적으로 어려운 상황이어서 global reference를 만들자
global reference를 만들기란
ex) 고화질의 이미지를 다루는 프로그램이 있는데, 이 프로그램이 좀 더 성능이 좋은 프로그램으로 옮겨야 할 일이 생겼다. 하지만 고화질의 이미지를 모두 다 옮기기에는 실질적으로 어려우니까 reference를 두자. 즉, 새로 이동하는 머신과 원래머신 간에 connection을 맺어서 파일을 access 할 수 있는 reference를 만들자. 그러나 로컬에서 사용하던 이미지를 네트워크를 통해서 받다 보니까 사용량이 많아질경우에 퍼포먼스에 문제가 생길 수 있다.
즉, global reference란 리소스를 그 위치에 그대로 두고 프로세스만 이동을 하는 것, 그리고 원격으로 기존위치에 있는 리소스를 액세스 하는 방법을 만드는 것이다.
리소스가 value에 의해 바인딩되고
- 또한 그 리소스가 fixed라면 : 하드웨어 머신에 매어있기에 이동은 불가능하다. 즉, global reference를 두자 ex) memory
- 또한 그 리소스가 fastened라면 : 사실상 이동하기에는 힘들자. 그래서 이동한 새 머신에 같은 value를 갖는 라이브러리가 있다면 사용이 가능함 or global reference를 사용하자
- 또한 그 리소스가 unattached라면 : 옮겨라, 그러나 다른 사용자와 같이 쓰고 있다면 옮기면 안 된다.
리소스가 type에 의해 바인딩될 경우
- 서로 옮겨간 머신 쪽에 같은 type의 리소스에 다시 바인딩해서 사용하자.
- 같은 type의 리소스가 없다면 copy 하거나 global reference를 사용하자
heterogeneous 한 시스템으로 migration 할 경우
- 프로세스하나를 이동하는 게 아니고 프로세스의 실행환경까지 모두 옮겨야 함. 그럼 리눅스에서 돌아가는 것과 윈도에서 돌아가는 것이 서로 다를 텐데 이 문제는 가상머신을 써서 heterogenous 한 시스템에서 이동이 가능하다.
그럼 전체 실행환경의 메모리 이미지와, 로컬 리소스를 어떻게 이동시킬까?
- 현재 머신에서 다른 머신으로 메모리를 모두 이동을 시키고, 기존에 돌았던 실행환경을 멈추지 않고 현재 메모리상태를 다 copy 함(즉, 가능한 한 실행을 멈추지 않고 메모리를 쫙 보내고 전송 중에 바뀐 메모리 부분을 다시 쫙 보내기)
- 현재 가상머신을 정지시키고 메모리를 다 이용하고, 새로운 곳에서 다시 시작. 그러나 리소스를 사용하는 클라이언트가 있다면 그 클라이언트는 사용을 못함(migration시간이 가장 짧은 방법)
- 새로운 페이지에서 내가 필요한 메모리들만 가져오기, 지금 당장필요한 가상머신을 돌리는데 필요한 메모리만 빠르게 받고 새 머신에서 바로시작을 하는 방법이 고 필요한 메모리가 있으면 그때그때 새로 가져옴(migration전체가 끝날 때까지 시간이 오래 걸림), 즉 migration시간이 제일 길다. 그러나 새 머신에서 가장 빨리 돌리는 방법임
'Computer Science > 분산시스템' 카테고리의 다른 글
| [분산 시스템] Synchronization (0) | 2024.06.03 |
|---|---|
| [분산 시스템] Naming (0) | 2024.05.12 |
| [분산 시스템] Communication (0) | 2024.04.15 |
| [분산 시스템] Architectures (0) | 2024.03.31 |
| [분산 시스템] Distributed System (0) | 2024.03.29 |