Layered protocols
컴퓨터 네트워크에서 사용자 간의 규약이 많이 필요하다.
그래서 만든게 OSI model
OSI model
지금은 사용을 잘하지 않으나, OSI model에서 사용했던 layered로 구분하는 방법은 좋은 방법이었다.
communication의 두 가지 타입
- connection oriented protocols(TCP) ex) 전화
- connectionless protocols(UDP) ex) 편지

왜 이런 식으로 layered를 나눌까? 관리가 수월 해질 수 있음, 다른 레이어드를 신경 쓰지 않고 자신의 레이어드만 신경 쓰면 되기 때문, 구체적인 통신방식이 밑 레이어드에서 바뀔 수 있으나 인터페이스만 유지가 된다면 윗레이어드는 밑레이어드의 변경에 영향을 받지 않고 소통을 할 수 있다는 장점이 있음
- Physical layer : 물리계층, 0과 1을 다루는 계층으로 0과1을 어떻게 다뤄야 하는지 프로토콜로 규약을 맺어야 한다.
- Data link layer : 내가 받는 bit들이 에러가 발생하는지 아닌지 체크하는 계층, checksum을 주로 하는 계층(내가 데이터와 checksum value를 같이 보냄, 받는 쪽에서는 똑같은 방식으로 checksum값을 계산을 해서 내가 계산한 value와 헤더에 담긴 value가 같은지 비교해서 무결성을 체크하는 방법)
- Network layer : 주로 routing을 하는 계층, ip주소를 보고 패킷을 주소 방향으로 routing 해줌. IP주소로는 목표로 하는 컴퓨터까지만 전달이 되고 최종으로 전달하는 것은 포트번호로 구분을 함.
- Trasport layer : 포트번호를 가지고 대상 프로세스에게 전달해 주는 역할을 함, 이 계층에서는 메시지가 너무 길면 작은 조각으로 쪼갠다. 순서대로 쪼개서 순서 그대로 보내줌(TCP의 경우)
- Session layer : 세션과 관련된 프로토콜을 정의해 둔 계층, 커뮤니케이션하는 동안에는 세션이 유지되고 끝나는 순간 세션은 없어짐
- Presentation layer : 보내는 메시지의 표현과 동작을 담당하는 계층, 서로 heterogenous 한 프로세스들끼리 통신을 할 때 presentaion계층이 포맷을 싹 다 바꿔줌(A가 B에게 보낼 때 B가 이해할 수 있는 포맷으로 바꿔줌)
- Application layer : 애플리케이션마다 자체적으로 서로 통신하는 프로세스들 사이에 통신할 수 있도록 만들어진 규약, 또한 애플리케이션 종류가 달라도 표준으로 사용하는 프로토콜들이 있다. ex) file transfer protocol(FTP)(파일을 전송할 때 표준으로 정해진 약속), HTTP
Middleware protocol : APP과 Trasport layer사이에 위치해 있음. 미들웨어를 사용하는 애플리케이션이라면 TCP, UDP를 사용해서 통신하는 게 아니고 미들웨어를 이용함. 그럼 그냥 안 쓰고 해도 되지 않나? 가능함, 그러나 분산투명성을 보장할 수 없고 TCP, UDP만으로 부족한 부분이 있음
미들웨어가 제공하는 서비스들
1. 일반적인 미들웨어 서비스 ex) authentication protocols(사용자 인증), authorization protocols(사용자 권한), commit protocols(atomicity를 지원해 줌. 즉, 10개의 쿼리를 날렸을 경우 10개가 다성공하면 리턴을 해주고 하나라도 틀리면 롤백시키는 것), distributed locking protocols
2. 커뮤니케이션 특화 서비스 ex) RPC(메시지를 서버에 직접적으로 보내지 말고 클라이언트가 원하는 서비스가 있다면 함수를 호출하듯이 서비스를 제공하는 것), real-time data를 주고받을 때 세팅과 동기화해줌, reliable multicast 서비스를 제공

types of communication
- persistent vs transient
- synchronous vs asynchronous
- discrete vs streaming
persistent communication : 오프라인이더라도 메시지를 중간에 저장을 해서 온라인상태가 될 경우에 전달해 주는 커뮤니케이션 ex) email
transient communication : 보내는 쪽과 받는 쪽이 온라인 상태여야 한다.(TCP, UDP)
asynchronous communication : 메시지를 보내고 상대방의 응답을 기다리지 않고 다른 태스크를 수행하는 방식
synchronous communication : 메세지를 보내고 상대방의 응답을 기다리고 다음 테스크를 수행하는 방식
persistence synchronizaton : message-queuing systems
trasient synchronization : ex) RPCs
email 같은 경우: persistent asynchronous
chat app 같은 경우 : 대부분의 경우 asychronous 하고 경우에 따라 persistent or transient 하다.
여기까지가 중간고사 범위
types of communication
persistent : 중간에 애플리케이션이 보내는 메시지가 상대방이 받지 못할 상태일 때 중간에 미들웨어에서 저장을 해서 전달이 되는 경우(받지 못할 상태에서도 받음)
transient : 위의 내용과 반대(받을 수 있는 상태에서만 받음)
synchronous : 동기적인 통신은 보내는 프로세스가 메시지를 보낸 다음에 상대방의 응답이 올 때까지 다음작업을 수행하지 않고 기다리는 상태
asynchronous : 위와 반대로 메시지를 보낸 다음에 상대방의 응답을 기다리지 않고 다음작업을 수행함
email은 무슨 통신일까? app레벨에서는 사용자가 보낸 이메일에 대한 응답을 기다리지 않기 때문에 asynchronous 하다고 볼 수 있고 tcp계층에서 tcp는 신뢰적전송을 중요시하기 때문에 사용자가 email을 받았는지 안 받았는지를 확인을 해야하기 때문에 synchronous하다고 볼 수 있다.
persistence synchronous의 조합을 message-queing systems라고 한다. 많은 경우에 message-queing시스템은 synchronous 하다고 볼 수 있다.
zeroMQ : tcp이상의 통신방식을 지원해 주는 메시지 큐. pub-sub타입의 통신도 지원해 줌
MPI(message passing interface) : 프로세스들 사이에 메시지를 주고받을 수 있는 함수들이 여러 가지, 즉 여러가지 방식으로 보내고 받을 수 있음.
기본적인 메세징 기능은 trasient 하다.
transient communication과 synchronization
ex)
RPC(Remote Procedure Call) : 중간에 메시지를 저장하는 것이 기본적으로 없다. 그렇기 때문에 transient 하다. 기본적으론 원격에 호출하고 응답메시지를 기다리기 때문에 snchronous 하다고 볼 수 있다.
RPC를 사용하는 목적은 서버에 서비스를 요청하는 방법, 사용 편의성을 높여주기 위해서 사용. 로컬함수를 호출하듯이 서버에서 제공하는 서비스를 로컬함수를 호출하는 것과 똑같은 방식으로 호출을 해서 리턴값을 받는 형태로 서비스를 이용. 분산 투명성 제공
- RPC
count = read(fd, buf, nbytes)
read() 함수는 fd라는 파일로부터 바이트를 읽은 다음에 읽은 데이터를 buf array에 리턴을 한다.

함수를 이용해서 파라미터를 넘길 때 그 파라미터를 넘기는 방식에 따라서 call-by-value와 call-by-reference로 나눠진다.
- call-by-value : 갑 자체를 파라미터로 넘겨주는 방식. read() 함수에서 fd, nbyte와 같은 파라미터의 예처럼 값 자체를 스택에 씀. 그리고 그 값은 함수가 실행이 다 완료되고 난 다음에 값이 중간에 변경되지 않는다.
- call-by-reference : 이 방식도 스택상에 값을 넣는 방식인데 이 값이 실제값이 아닌 주소값이다.
위의 방식을 RPC에 그대로 적용할 수 있을까? call-by-value는 요청 메시지를 보낼 때 파라미터 값을 그대로 요청 메세지 안에 넣으면 되기때문에 아무런 문제가 되자않음. 반면에 call-by-referenece는 주소값을 보내야 한다. 이 주소값은 로컬에서만 의미가 있는것이기 떄문에 서버입장에서는 의미가 없다. 그래서 주소를 그대로 보낼 수가 없다. RPC로 하기 위해선 요청 메세지를 보낼떄 주소값을 그대로 보내는것이 아니고 주소값이 나타내는 데이터를 다 보내야한다. 그래서 RPC에서 call-by-referenece대신에 call-by-copy/restore 방식을 사용한다.
read()를 RPC로 만들면 fd는 local에서만 의미가 있음(서버에서는 의미 X), 또한 fd를 얻을 수 조차 없다. 그렇기 때문에 read는 local에서 실행하면 안보다 서버에서 실행해야 함. 즉, 원격에 있는 함수를 클라이언트가 요청하는 방식.

1. 클라이언트가 RPC를 호출한다.
2, 클라이언트 stub이 로컬 메시지를 만들어서 로컬 OS를 호출한다.(왜 호출하냐면 소켓을 통해서 서버로 메시지를 직접 보내야 하기 때문에, 소켓을 이용해서 보내려면 애플리케이션은 transport레이어 서비스를 이용해야 함. tcp를 사용하려면 요청을 해야 한다. tcp소켓은 OS가 관리하기 때문에)
3. 클라이언트 쪽 OS가 미들웨어가 만든 요청 메시지를 remote OS(서버)로 보내준다.
4. 서버의 OS가 메세지를 받고 위에 있는 server stub으로 메세지를 올려준다.
5. server stub은 메세지를 받았으면 unpack(언마샬링)해서 메세지를 모아가지고 어떤 함수를 호출하고 어떤 파라미터로 호출할 것인지 분석을 해야 한다. 그래서 server stub이 직접 호출한다는 얘기는 서버에 구현된 함수를 직접 호출한다는 얘기다.
6. 그러면 서버의 함수가 실행이 되고 server stub으로 리턴값을 준다.
7. server stub이 리턴값을 이용해서 응답 메시지를 만든다. 그안에 리턴값도 담고 아웃풋 파라미터값도 다 담음
8. OS를 통해서 응답 메세지를 보낸다.
9. 클라이언트의 OS가 응답 메세지를 받으면 그것을 자기 위에 있는 클라이언트 미들웨어(client stub)로 보내준다.
10. 클라이언트 미들웨어는 받은 응답 메세지를 다시 리턴값이 뭔지 아웃풋 파라미터가 뭔지 해석을 해서 클라이언트 application에게 보내준다.
1번과 10번은 클라이언트에게 보이는 내용이고 2번부터 9번까지는 미들웨어가 숨겨주는 역할을 한다.
- 마샬링 : 메시지로 만들어주는 절차
- 언마샬링 : 메시지로부터 그 메시지가 의미하는 바가 뭔지 거꾸로 해석하는 방식
클라이언트 stub과 서버 stub은 둘 다 마샤링과 언마샬링을 가지고 있음
클라이언트는 클라이언트 애플리케이션이 호출하는 함수의 내용을 보고 요청 메시지로 마샬링 하는 절차를 거친다.
클라이언트 stub이 서버로부터 응답 메시지를 받으면 그 메세지를 언팩(언마샬링)한다.
서버도 요청메시지를 받으면 그거를 언마샬링 해서 의미를 파악한 다음에 해당 함수를 호출해 주고 리턴값이 있으면 리턴값을 보내야 한다면 리턴메세지를 만들어야하니 리턴메세지로 마샬링해서 보내준다.

RPC를 개발을 할 때 heterogenous 하다면 서버와 클라이언트 간에 해석이 서로 다를 수 있다는 문제점이 있다.
ex) 인코딩방식이 다를 수 있음, 숫자도 음수값을 표현할때도 다를수있음
실질적으로 느끼는 heterogenous 한 case는 숫자를 바이트 단위로 표현할 때, 바이트 단위로 숫자를 표현하는 방식(endian)이 달라질 수 있다.



RPC를 이용해서 파라미터를 요청메시지로 만들어서 보낼 때 pointer or reference parameter일 경우엔 어떻게 할까?
포인터는 로컬에서만 의미가 있는 숫자이기 때문에 주소값을 그대로 넣는 것은 의미가 없음.
해결책으로 아예 쓰지 못하게 만들어 버리는 방법이 있음. 혹은 포인터가 가리키는 실제데이터의 값을 메시지 안에 다 넣어 버린다는 방식. 하지만 이러한 방식은 파라미터 전달방식에서 call-by-copy/restore방식을 차용하게 된 것이다.(주소값을 그대로 사용할 수없이 때문)
RPC의 장점 : application이 서비스를 쉽게 이용할 수 있다.
단점은 :퍼포먼스가 떨어진다. 왜? 미들웨어에서 해야 할 일이 많음(메시지 만들고 받은 메세지 다시 해석해야 됨) 또한 응답하려는 메시지가 커질 수가 있음. 그래서 가능한 한 메시지의 크기를 줄일 수 있으면 줄여야 한다.
ex) 만약에 미들웨어(stub)가 파라미터가 input파라미터인지 output파라미터인지 알고 있다면 메시지 안에 넣지 않아도 된다. 아웃풋 파라미터인 경우에는 요청메세지에서 빼도 된다.아웃풋 파라미터는 클라이언트가 필요로하는것이기 떄문에.리플라이 메세지안에서는 리턴값과 아웃풋 파라미터 값은 넣어줘야 한다. 왜냐면 클라이언트가 필요로하기 때문. 인풋파라미터는 응답메세지 안에서는 빼도 된다.
RPC에서 클라이언트와 서버사이에 메세지 안에 들어가는 데이터의 의미를 서로 똑같이 알고 있어야 잘 돌아간다. 즉, 클라이언트와 서버가 마샬링 하고 언마샬링 하는 방식이 똑같아야 한다. 그래야 의미가 변질되지 않기 때문에

Asynchronous RPC
ex) 돈을 다른 계좌에 보낼 때, 데이터베이스에 엔트리 추가, 리모트 서비스를 요청, batch 프로세싱등과 같은 방식들은 응답을 기다릴 필요가 없다.

클라이언트가 요청을 하고 자기는 다른 일을 하겠다는 방식이 Asynchronous RPC이고 다른 이름으론 One-way RPC가 있다.
One-way RPC방식을 사용하게 될 경우 문제가 발생할 수 있음 : 자기가 보낸 메시지가 잘 갔는지 중간에 사라졌는지 알 수가 없다. 또한 내가 보낸 요청이 전달이 됐는지 안 됐는지 확인조차 안 하겠다는 방식임
이걸 왜 쓸까? 가능한 한 빨리 메시지를 보내야 할 때 쓰고, 클라이언트가 요청을 한 번만 보내는 것이 아니고 주기적으로 보낼 때 사용함
RPC는 클라이언트가 요청을 보낼 때 서버 쪽도 돌고 있어야 하기 때문에 transient 하다. synchronous 하기 때문에 응답이 올때까지 기다려야 한다. 이것을 보완하기 위해서 나온 것이 messaging이다.(우리가 익히 알고 있는 소켓을 이용한 통신 방법)
소켓이란? app이 transport layer의 서비스를 사용하기 위한 수단
message oriented transient comm. berkeley socket
1. socket
2. tcp socket primitives
- socket : OS에게 socket을 만들어달라고 요청을 함.
- bind : 요청을 한 뒤에 로컬컴퓨터의 주소와 위에서 만든 소켓을 서로 연결시켜 주는 역할. bine는 주로 위에서 만든 소켓과 포트를 서로 바인딩 시킴 ex) 서버는 주소와 포트 번호를 함께 소켓으로 바인딩해야 한다. 즉, 바인딩이란 OS에게 메시지를 받을 건데, 내가 지정한 port번호로만 받겠다고 지정하는 것. 클라이언트 측면에서 바인딩은 필요하지 않다. 왜냐하면 OS가 port번호를 알아서 할당을 해주고 그 클라이언트의 포트번호는 서버와 연결을 맺는 과정에서 서버 측에서도 당연히 전달이 되기 때문에 애플리케이션이 신경 쓸 필요가 없다.
- listen(server side) : 서버 측에서만 호출할 수 있는 함수. non blocking형태로 호출하는 함수로 ㅇ 소켓을 사용하는데 충분한 버퍼공간이나 리소스를 할당해 달라고 OS에게 요청하는 것
- accept(server side) : blocking함수로 listen을 하고 난 뒤에 클라이언트로부터 연결을 기다리겠다고 하는 것. 클라이언트로부터 연결요청이 들어오면 OS가 그 클라이언트와 통신할 새로운 소켓을 생성하고 accept함수가 리턴을 해준다. 처음에 클라이언트의 연결을 기다리기 위해서 만든 소켓은 연결을 기다리는 용도로만 사용되고, 클라이언트랑 직접 메시지를 주고받는 소켓은 아니다. 그래서 서버소켓이라고 부른다.
- connect(client side) : OS에게 연결요청을 하는 것으로, tcp이기 때문에 메시지를 주고받기 위해서 먼저 요청을 해야 한다.
- send, receive : 클라이언트와 서버 간의 연결이 맺어지고 난 뒤에, 클라이언트는 자기가 만든 소켓을 가지고 서버는 accept에서 리턴된 소켓으로 메시지를 주고받으면 된다.
- close : 다 쓰고 난 뒤에 소켓객체가 사용했던 리소스를 OS에게 반환해 줘라고 요청하는 함수(이것으로 자원의 낭비를 막는다)


RPC는 synchronous 해야 하고 trasnient 해야 한다. socket을 사용하면 transient 해야 하고 app입장에서는 asynchronous 하다고 볼 수 있다. tcp입장에서는 패킷마다 보내고 받았는지 확인해야 하기 때문에 synchronous 하다.
messaging을 사용하면 RPC와 비교했을 때 미들웨어가 없기 때문에 좀 더 성능상으로 좋을 것이다. 소켓을 사용해서 불편했던 점이 persistent 하지 못했다는 것이다. 그래서 나오게 된 것이 message-oriented persistent comm.이다.
message-oriented persistent comm.
message queing system or message-oriented miiddlewatr(MOM)이라고 부른다.
que의 역할은 메시지를 저장하는것이고 상대방에게 메세지를 보내는 것이 아니고 que를 통해서 보내는 것이다. 상대방이 떠있다면 보내고 그렇지 않다면 que에 저장한다. ex) email
queing system은 메시지를 que에 보내고 다른 작업을 해도 되기에 asychronous 하다. que를 이용하기 때문에 persistent 하고 보내는 쪽과 받는 쪽이 동시에 떠있을 필요가 없다.
queing system은 자신만의 private 하거나 share 한 que를 가지고 있다.

메시지는 목적지를 지정해야 한다.
app에서 queing system을 사용할 때 이런 종류의 함수가 있다.
- put : que에 메시지를 넣겠다. non-blocking call(que가 꽉차면 바로 리턴을 받아서 에러코드를 실행)이다. blocking모드(que가 자리가 날때까지 계속 기다리는 것)로도 가능하다.
- get : que로부터 메세지를 가져오겠다. blocking call(que가 비어있을 경우에 읽을 때까지 계속 기다림)이다. non-blocking(que가 비어있으면 읽어 들일 메시지가 없다는 리턴값과 함께 바로 리턴)도 가능. 또한 longest pending message를 queue에서 제가 할 수 있다. 즉, que는 FIFO이기 때문에 먼저 들어간 애가 먼저 제거된다. 또한 조금 더 가공을 하여서 que에 있는 메시지를 구분해서 특정 메시지만 뽑아오도록 할 수 있다.
- poll : get함수의 nonblocking버전으로 읽어올 메시지가 있는지 물어보는 것 없으면 바로 리턴
- notify : handler라는 애를 queing system에 등록하는 것. 내가 다른 일을 하는 중에 메시지가 들어오면 나한테 알려줘라고 요청하는 함수. 어떻게 알려줄까? notify함수를 통해서 callback함수를 애플리케이션이 밑에 있는 미들웨어에 등록을 해둔다.즉, 애플리케이션의 함수를 미들웨어에 등록을하는것(이것이 handler) 그러면 미들웨어는 que에 메세지가 들어오면 등록된 handler함수를 호출을 해준다. 밑에 있는 미들웨어가 위에 있는 app함수를 호출하기에 callback이라고 부름. 즉, 핸들러란 미들웨어에서 자동으로 호출을 해주는 callback함수이다.
message-oriented persistent comm. general architecture
기본 제한사항
- 나랑 같은 머신이나 근처 머신으로 que를 보낸다(이러한 것을 source queue라고함)
- 거꾸로 읽을 때는 local queue로부터 메시지를 읽어 들이겠다.
- que를 통해서 메시지를 보내는 포맷 안에는 destination queue에 대한 정보가 있어야 한다.
- message queing system은 메시지를 목적지 que까지 메세지를 전달한다.
그래서 queue를 관리를 하자.
queue manager : que를 관리하는 미들웨어
queue manager 중에서 특수한 역할을 하는 애가 있는데 relay 또는 router(여기서의 라우터는 app계층의 라우터)라고 호칭한다. que와 que사이의 메시지들을 라우팅 해주는 역할을 하는 것을 relay or 라우터라고 한다. 헷갈리니 relay로 통일함.
relay의 주역할은 목적지까지 메시지를 보내주는 역할. relay가 왜 필요하지? 많은 message queing system에는 general 한 naming 서비스가 없다(app이 내가 통신하고자 하는 목적지 컴퓨터들의 주소를 app이 다 알고 있어야 함. 즉 관리 문제가 생긴다) 이문제를 해결하기 위해서 app밑에 relay역할을 하는 que manager를 따로 두자. 따로 두게 되면 app은 나의 que manager와 옆에 있는 릴레이만 알면 된다. 나머지 모든 주소정보는 relay애들끼리만 알게 하자. 그래서 주소가 변경되면 relay에서 처리할 수 있도록 하자.

relay를 사용하는 또 다른 이유가 있다. 바로 secondary processing이 있을 때
2차 처리라는 것으론 어떤 것이 있을까? 메시지가 logged 돼야 할 필요가 있을 때, 여기서 2차 처리는 logging 하는 것
또는 어떤 특별한 relay가 메시지의 포맷을 바꿀 수 있다.
message broker라는 애도 나오게 되었다. relay가 2차 처리를 하는 기능을 수행할 수 있는 것
즉, que manager, relay, message broker 모두 app입장에서는 밑에서 돌아가는 미들웨어이다.
그래서 broker를 이용해서 서로 다른 app들이 통신을 할 수 있게 된다.(메시지 변경 뿐만아니라 공통의 미들웨어를 사용해서) 만약 메세지 중개인이 없다면 서로 다른 app끼리 통신하려면 메세지 정보를 모두 알아야하고 새로운app이 추가되면 app들이 새로운 메세지 포맷에 대해서도 모두 알아야하는데 이러한 역할들을 브로커가 app대신 해준다.
서로다른 app들이 integration 하려면 가장 좋은 해결책은 공통으로 사용할 메시지 포맷을 만드는 것이다 그러나 이 방법은 가 어려움. 그래서 2차적으로 생각할 방법이 메세지 중개인 사용하는 것이다.

중개인이라는 메시지 기반 커뮤니케이션을 더 확장시키면 EAI(enterpirse application integration) 환경에서 서로다른 app들을 통합시킬 수 있다. EAI에서 사용하는 메시지 브로커는 모든 메세지 포맷을 알고 있기 때문에 서로다른 그룹의 app들이 각자 자기들끼리 메시지를 주고받는것도 전달해 준다. 즉 pub/sub모델처럼 메세지를 보내면 브로커가 그 메세지가 어디로 가는지 알게된다. 그래서 이 메세지를 이해할 수 있는 app에게만 메세지를 전달해준다. 그래서 관심메세지로 등록한 app에게만 메세지 브로커가 publish된 메세지를 전달해준다.
message queuing system이 사용되는 대표적인 예로 email, workflow, groupware, batch processing 등이 있다.
Stream-oriented communication
데이터는 discrete과 stream으로 분류할 수 있다.
discrete data는 데이터가 하나의 완전한 독립적인 의미를 갖지 않는 것(지금까지 봤던 왔다 갔다 하는 데이터들)
stream data는 멀티미디어 데이터를 의미한다. (멀티미디어 사운드 or 비디오)
소캣 레벨에서 데이터를 보내는 것은 둘 다 똑같다. 그러나 스트림 데이터인 경우 app들이 고려해야 할 사항들이 있다.
스트림 데이터를 보낼 때는 타이밍이 가장 중요하다. 스트림 데이터인 경우 전송하기 전이나 후에 처리해야 할 사항들이 더 있다. 타이밍에 따라서 3가지로 분류가 된다.
Asynchronous transmission mode : 데이터를 이러한 모드로 보낸다는 것은 타이밍 constraint(제약, 강제)가 없다는 뜻이다. 즉, 비동기적으로 언제든지 도착만 하면 상관없다는 뜻이다. ex) 파일 전송 : 빨리 전송하는 것보다 파일이 다 보내지는 것이 중요
Synchronous transmission mode : 데이터를 이러한 모드로 보낸다는 것은 타이밍 constraint(제약, 강제)가 있다는 뜻이다. maximum end-to-end delay가 있다. 최대 딜레이 값이 정해져 있어서 정해진 딜레이 값 안에서는 무조건 전송이 돼야 한다. ex) 날씨 or 온도 데이터들 : 늦어지게 되면 의미가 없는 데이터가 되기 때문
Isochronous transmission mode : maximum end-to-end delay와 minimum end-to-end delay가 있다. 데이터를 늦게 보내도 안고 너무 빨리 보내도 안된다.
스트림 데이터는 simple 데이터와 complex 데이터가 있다.
simple stream data : 스트림 데이터의 종류가 한 가지이다.
complex stream data : 두 가지 이상의 스트림 데이터가 연관되어 있다. (스테레오 오디오(죄, 우 사운드가 합쳐짐) or 영화(이미지 + 소리가 합쳐진 것)) 콤플렉스 스트림은 심플에 비해 더 복잡하다. 왜냐하면 두 가지 데이터 모두 타이밍을 맞추는 것은 중요하고 거기에 추가로 연관된 스트림들 간의 싱크를 맞춰야 하기 때문에(동기화 작업)

그럼 qos에서 퀄리티라고 하는 것이 무엇이 있을까?
- 멀티미디어 전송 세션을 설정하는데 걸리는 딜레이
- end-to-end delay : 전송을 해서 클라이언트 app이 메시지를 받을 때까지 걸리는 delay
- delay variance : 딜레이의 변화량(jitter)
jitter : 메시지 전송이 될 때 변동값이 심하다. 딜레이가 클 때가 있고 작을 때가 있음 전반적인 평균 딜레이는 작은데 변동값이 큰 경우하고 변동값은 작은데 딜레이가 큰 경우가 있는데 이때 jitter값이 작은 게 좋다고 한다. jitter 값이 작다는 것은 딜레이가 큰 범위 안에서는 느리게 플레이되는데 규칙적으로 플레이된다는 뜻이다. 즉, 느릴 뿐 끊김 없이 플레이가 된다는 뜻이다. jitter값이 크다는 것은 빠르게 플레이되지만 끊겼다가 빠르게 플레이됐다가 반복이 된다. 이러면 더 불편함이 커진다. 그래서 jitter를 줄이기 위해서 버퍼를 사용하자.
- round-trip delay : 갔다가 받는데 까지 걸리는 시간
- 비트 전송비율
그래서 데이터 스트림에서의 qos는 timeliness, volume, reliability 3가지가 있다. 멀티미디어 데이터를 보낼 때 reliability보다 timliness측면이 중요하다. 그래서 tcp udp중에서 udp를 하는경우가 많다. 그래서 데이터 스트림을 보낼때 qos를 맞추는 것이 중요한데 어떻게 할 수 있을까? 네트워크 레벨과 app레벨의 해결책으로 나눠진다.
- network level solution : transposrt layer나 밑에 layer에서 적용하는 기술들이다. 멀티미디어 퍼밋은 다른 패킷보다 빨리 가야 하니까 우선순위를 두어서 빨리 가야 하는 패킷들은 빨리 보내주는 역할을 한다.
- application level solution : 가장대표적인 것이 버퍼링이다. 멀티미디어 데이터를 처리할 때 버퍼를 두어서 어느 정도 쌓아지면 스트리밍 한다. 버퍼를 통해서 jitter를 줄여준다. 그러나 버퍼링도 문제가 있다.

app에서 버퍼링문제를 해결하기 위해 어떻게 해야 할까?
극단적인 예시로 처음부터 끝까지 버퍼링을 하자. 그럼 끊기지 않을 테지만 버퍼링이 될 때까지 전부 다 기다려야 한다.
그렇기 때문에 버퍼링도 적당히 하고 기다리는 시간도 짧게 해야겠다.
app에서 또 다른 문제가 있다. 이러한 문제들을 해결하기 위한 해결책으로 아래와 같다.
- forward error correction(FEC) : UDP로 보내게 되면 패킷이 중간에 없어질 수 있는데 그러면 패킷을 다시 보내야 한다. 그런데 FEC를 사용하면 패킷을 다시 보내지 않고도 복구할 수 있게 된다. 원래 보내는 데이터 패킷 안에 추가 데이터를 넣는다. FEC가 적용된 패킷을 받고 중간에 빠진 패킷이 있다는것을 알게되면 내가 받았던 패킷들만으로 받지못한 패킷의 정보를 알 수 있게 된다.
- interleaving frame technique : 하나의 패킷안에 데이터를 순서대로 넣지 말고 섞어서 넣자.

스트림 데이터 중에서 콤플렉스 스트림인 경우에 동기화도 중요한 qos 포인트가 된다.



스트림 데이터 간에 동기화를 하려면 싱크와 관련된 메타 데이터가 필요하다. 어떤 타이밍에 어떤 데이터가 플레이가 돼야 하는지에 대한 정보가 필요하다. 그런데 이러한 정보들은 보내는 패킷 안에 추가적으로 다 포함이 되어있다. 그래서 보내는 쪽과 받는 쪽에 데이터 안에 있는 싱크정보를 보고 동기화를 진행을 한다. 그래서 보내는 쪽에서 싱크를 할지 받는 쪽에서 싱크를 할지로 나눠진다.
보내는 쪽에서 싱크를 맞춰서 보내는 것이 더 나은 방법이다. 왜냐하면 받는 쪽에서는 싱크 걱정할 필요없이 받는 데이터를 플레이하고 플레이 타이밍만 신경을 쓰면된다.
그러나 받는쪽에서 싱크를 하게 되면 받는 쪽에서 모든 부담을 다 갖게 된다.
그래서 스트림 데이터는 discrete 데이터와 다르게 스트림 데이터를 전송을 하려면 타이밍 constraint를 추가적으로 고려를 해야 한다. 또한 complex 스트림인경우에는 두가지 이상의 스트림간에 동기화도 고려를 해야한다.
Multicast communication
unicast : 1:1 통신 tcp. udp 같은 통신
multicast : 1: n 통신
유니캐스트는 한 명 한 명에게 하나씩 보내지만, 멀티캐스트는 한번 보내는 대신에 라우터가 이 데이터를 다른 애들에게 보내줌
멀티캐스트를 사용하면 보내는데 필요한 네트워크 리소스를 절약할 수 있어서 좋지만 단점도 있다.
1. communication path를 어떻게 설정해야 할지 고민을 해야 한다. 효율적인 path가 어디인지 찾아야 하는 복잡성이 있음
2. 관리자가 멀티캐스트를 관리하는데 드는 비용이 들 수가 있다.
3. ISP입장에서는 멀티캐스트를 서포트하기를 꺼려한다. ex) 멀티캐스트로 메시지를 보내고 관심만 있다면 그 주소로 join한 app들한테 메세지가 전달이 되기 때문에 상업용으로는 과금을하기 힘들기 때문에 선호하지않는다. 왜냐하면 쓴만큼 돈을 받아야하는데 멀티캐스트를 쓰면 누가 메세지를 맡는지 파악을 하기 힘들기 때문에
그래서 라우터 레벨에서 멀티캐스트를 지원을 하나 실질적으로 사용하기 힘든 부분이 많아서 app 레벨의 멀티캐스트 기술이 대안으로 나왔다.
기본적인 app 레벨의 멀티캐스트 기술은 내가 그 대상에게 직접 전송하는 것이 아니고 나는 한 번만 전송을 하고 나머지는 app들이 path를 따로 구성을 해서 목적지까지 전송을 해주는 방법이다. 그럼 받고자 하는 app까지 어떻게 path를 만들까?
path를 두 가지로 나눌 수 있다.
tree or mesh
mesh는 path가 끊기더라도 다른 path가 있기 때문에 좀 더 robust 하다
대표적인 app레벨 멀티캐스팅기술로 Scribe system이 있다. chrod시스템과 비슷한 p2p기술을 사용한다.
먼저 멀티캐스트 트리의 루트를 찾아야 한다. 하나의 노드가 멀티캐스트 세션을 시작하려고한다.(메시지를 보내고싶어한다는 뜻) 그러면 노드는 멀티캐스트 identifier라는 ID를 생성을 해야하는데 이것은 chrod 시스템과 비슷하게 랜덤키를 생성한다. 멀티캐스트 메세지를 보내려고 하는 노드는 생성한 멀티캐스트 ID를 가지고 succ를 찾아야한다. 그 succ가 멀티캐스트의 루트가 된다
메세지를 받고 싶으면 트리에 join 해야 한다.
join 하는 법
1. p라는 노드가 트리에 조인을 하고 싶다.
2. p는 LOOKUP과정을 통해서 mid의 succ를 찾아야 한다.
3. 조인 요청이 몇 가지의 노드들을 거쳐서 LOOKUP메시지가 전달이 된다.
4. 그렇게 전달되는 노드 Q가 만약 멀티캐스트 트리에 참여하고 있지 않은 노드라면 forwarder로 참여하게 된다. 그래서 Q노드는 포워더의 기능을 수행하게 된다. 그래서 p는 Q의 child가 된다. Q는 LOOKUP메시지를 계속 다음 노드로 전달을 해준다. 만약 그 다음 LOOKUP메세지를 받은 노드가 이미 참여하고 있는 노드였다면 LOOKUP메세지는 전달할 필요가 없다. 왜냐하면 내가 이미 멀티캐스트 메세지를 받을 수 있기 때문 (즉, 원래의 LOOKUP메세지는 MID라는 키를 관리하는 애가 누구인지 묻는 메세지이지만 멀티캐스트 스크라이브 시스템에서 멀티캐스트 트리에 조인을 할때 사용한다. 기존에 이미 멀티캐스트 트리에 참여하는 노드가 LOOKUP 메세지를 받을 때까지만 LOOKUP메시지가 전달이 된다. 그때까지 전달에 사용된 노드들은 다 트리상의 path에 추가가 된다.)
이렇게 트리가 구축이 되면 멀티캐스트는 어떻게 수행이 될까?
멀티캐스트 메시지를 보내려고 하는 노드는 단지 그 메세지를 mid의 루트쪽으로 전달을 해야한다. 여기서부터는 path를 따라서 쭉 전달이 된다. 그렇기 때문에 app레벨에서 멀티캐스팅은 overlay network를 어떻게 구성을 할지가 가장 중요하다.(노드들간의 path를 어떻게 구성을해야 효율적으로 메세지를 전달할 수 있을 것인지)
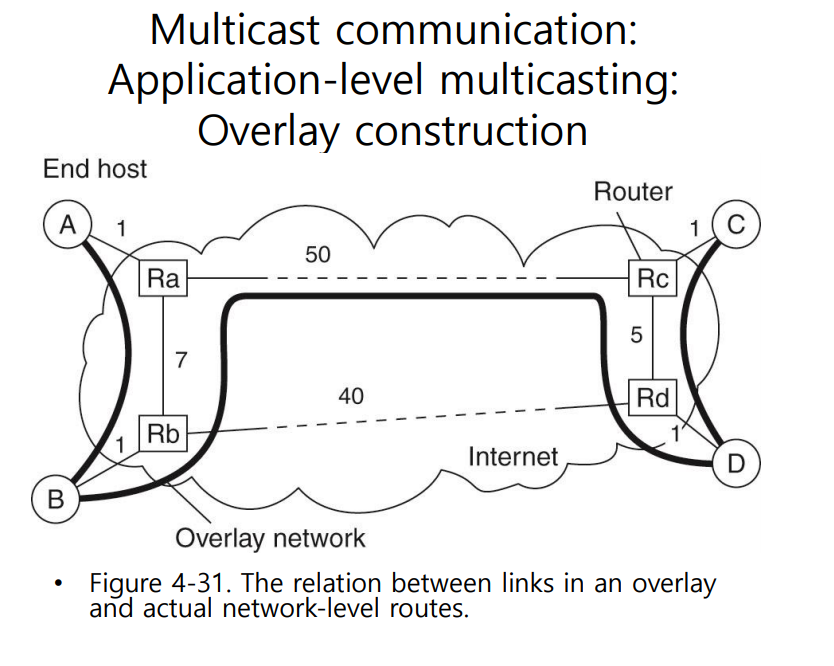

그럼 효율적인 트리라는 것은 뭐지? 3가지로 나눌 수 있다.
link와 stretch는 path하나하나의 코스트를 판단하는 기준이 되고 tree cost는 트리 전체의 코스트를 판단한다
Link stress : 하나의 링크가 받는 스트레스가 얼마가 되는 지를 수치화한 것 path가 중복적으로 사용이 될수록 스트레스를 받는다. 즉, 얼마나 많이 이 링크로 메시지가 자주 왔다 갔다 했는지에 대한 값을 수치화한 것. 그래서 링크 스트레스를 효율적인 트리를 만드는 기준으로 사용한다는 것은 각각의 링크의 스트레스를 최소화하는 방향으로 트리를 구성하겠다는 뜻
Stretch : 여러 path 중에서 최적의 루트 대비 현재 멀티캐스트에서 사용하는 링크의 코스트가 상대적으로 어떻게 되느냐를 나타낸 것. 스트레치 값은 비율로 나타내는데 분모에는 최적의 루트에서의 코스트값이고 분자에는 현재 사용하는 코스트값을 나타낸다. 스트래치값이 1이면 가장 좋은 스트레치를 사용하는 것이다. path에 쓰여있는 숫자가 작을수록 좋음. 그래서 스트래치 값이 작아지는 방향으로 트리를 구축해야 효율적이다.
Tree cost : 다양한 종류의 트리가 나올 텐데 이 트리의 코스트값이 가장 작은 트리를 선택을 하자.
ex) minimum spanning tree : 멀티패스트 패맛이 모든 노드에게 전달될 때까지 걸리는 시간이 가장 짧은 트리를 찾자.

이론적으로 위의 방법들로 최상의 멀티캐스트 트리를 찾을 수 있으나 시간이 너무 오래 걸린다. 그래서 대안으로 적당히 좋은 트리를 빨리 찾는 방법이 연구가 됐다.
rendezvous node(랑데부 노드) : 노드 중에서 특별한 노드를 하나 이용하는 것, 네트워크에 참여하는 노드들에 대한 정보를 많이 알수록 최상의 해결책을 찾을 수 있기 때문에 랑데부노드한테 노드들에 관한 정보를 가지고 있게 하자. 그래서 트리를 확장할 때에 랑데부에게 물어봐서 나의 최적의 부모를 누구로 할지 선택할 정보를 준다
최적의 부모를 찾는 것도 여러 가지 기준이 있다. 기준을 잘못 사용하면 star toplology 같은 예시가 있을 수 있다. star topology는 모든 노드들이 루트를 부모노드로 삼게 되는 것이다. 이러한 방법은 트리의 효율성이 떨어짐. 그래서 추가적인 제약이 필요하다. 예를 들어 루트밑에 자식의 개수를 제한시키는 것이다.
'Computer Science > 분산시스템' 카테고리의 다른 글
| [분산 시스템] Synchronization (0) | 2024.06.03 |
|---|---|
| [분산 시스템] Naming (0) | 2024.05.12 |
| [분산 시스템] Process (0) | 2024.04.05 |
| [분산 시스템] Architectures (0) | 2024.03.31 |
| [분산 시스템] Distributed System (0) | 2024.03.29 |