Name : 어떤 엔티티를 지칭하는 이름
Naming : 이름을 갖는 엔티티를 찾아가는 과정
Access point : 내가 찾고자 하는 엔티티에 액세스 할 수 있는 게이트웨이 역할
엔티티를 찾아가려면 일단 엔티티를 품고 있는 엑세스 포인트를 먼저 찾아가야 한다. 액세스 포인트자체도 별개의 엔티티이다. 그렇기 때문에 액세스 포인트의 이름을 알아햐 한다. 그 이름을 address라고 한다.
ex) 사람으로 치면 엑세스 포인트역할을 하는 것이 전화기이다. 어떤 사람에게 액세스 하기 위해서 그 사람이 가지고 있는 전화번호(address)를 알아야 한다.
ex) 내가 엑세스하고자 하는 서버 프로세스가 있다면 먼저 그 프로세스가 돌아가는 컴퓨터에 먼저 액세스 해야 한다. 그래서 그 호스트의 주소와 포트번호를 다 합쳐서 address라고 하는데 address를 찾아가서 서버 프로세스에 접근이 가능하다.
그럼 엔티티의 이름을 그냥 어드레스로 쓰면 편하지 않을까? 쓰기에는 좋지만 문제가 발생한다.
관리를 하는게 까다로워질 수 있다. 엔티티는 그대로인데 액세스 포인트는 바뀔 수가 있다. 그렇기 때문에 클라이언트 입장에서는 이름이 계속 바뀌는 거라 불편해질 수 있다. 그래서 별도의 이름을 쓰는 것이 더 효율적이다.

전화번호는 name은 될 수 있으나 ID는 될 수 없다. 전화번호는 바뀔 수 있다. 주민등록번호는 ID의 역할을 할 수 있다. 또한 지문이나 홍체 같은 생체정보도 ID의 역할을 할 수 있다. 1,2,3번의 조건이 만족이 되면 ID가 가능하다. 이름 중에 특별한 성질을 갖는 애가 둘이 있다. 바로 address와 ID이다. address는 access point의 이름을 address라고 지칭을 한다. 이름 중에서 위에 3가지 조건(유일성)이 만족된다면 ID라고 부를 수도 있다.
ID나 address같은 경우에는 컴퓨터입장에서 관리하기 편해야 하기 때문에 숫자로 표현이 된다. 또한 사람이 읽기 편한 이름이 있다. 일반적으로 캐릭터 스트링으로 표현된다.
naming systems : 이름을 짓는 방법에 대한 시스템이 아니고 특정이름을 갖는 리소스를 찾아주는 시스템.
분산시스템에서 naming한다라는 뜻은 어떤 이름이 있을 때 그 이름의 address를 찾는 과정이다(access point를 찾는 과정이다.) 그래서 access point만 일단 찾으면 그 access point가 품은 리소스를 찾는 거는 쉽다, 즉 naming과정은 acccess point를 찾는 과정이다. 그래서 이런 걸 하기 위해서 naming system에서는 어떤 이름이 있을 때 그 이름이 어떤 주소로 맵핑이 되는가에 대한 바인딩 정보를 가지고 있다. DNS라는 것도 이런 정보들을 유지하고 있다. 그래서 naming 하는 방법이 3가지로 분류될 수 있다. naming절차는 그 name이 flat인지 structured인지 attributed-based인지에 따라서 달라진다.
structured와 attributed-based는 찾기가 수월하다. 그러나 규칙에 따라서 이름을 지어야 한다. flat에 비해서 flat은 이름짓기는 쉽다. 그러나 찾아가기는 어렵다.
Flat naming
flat name은 unstructured name이라고도 한다. 구조가 없다라는것, 즉 이름 안에 어떤 의미가 없는 거다. 그래서 flat name에서는 ID가 random bit strings이다. 랜덤이기 때문에 이름이 가리키는 리소스에 대한 정보를 얻을 수 없다. 막 지었기 때문에. 그래서 flat name안에는 어떠한 정보도 들어있지 않다. naming을 하려면 리소스를 품는 access point를 찾아야 하는데 이 access point가 어디에 위치해 있는지에 대한 정보를 찾을 수가 없다. 그래서 찾기가 까다롭다. 그럼 어떻게 찾지? 진짜 아무런 정보가 없기 때문에 broadcast 할 수밖에 없다.
그래서 모든 flat name에 대한 address정보를 가지고 있는 서버가 있으면 걔한테 물어보자. 만약 이런 서버가 없는 P2P환경이라면 broadcast방법 밖에 없다. 이 이름을 갖고있는애가 누구인지 묻는 request 메시지를 만들어서 뿌려야 한다. 이 메시지를 받는 노드들 중에 내가 찾고 싶은 이름의 리소스를 가진 프로세스가 있으면 응답을 하라고 broadcast 해야 한다. 그러나 broadcast는 안 쓰는 것이 좋다. 비효율적이기 때문이다. 그래서 multicast를 사용하자. 이름을 찾기 위한 용도로 특정 멀티캐스트 주소를 하나 할당을 해서 그 주소에 조인한 노드들 중에 이름에 해당한 리소스를 갖고 있는 노드가 응답을 할 것이다.
flat name을 사용하는데 엑세스 포인트가 바뀌는 경우에는 forwarding pointer를 두자. 그래서 처음 액세스포인터를 사용하더라도 계속 접근이 가능하다. 그러나 이 방법을 사용하면 단점이 있다. 기존의 액세스 포인터 역할을 했던 컴퓨터들을 없앨 수가 없다. 또한 chain이 길어지게 될 경우에 fail날 확률이 높아진다. 비용도 높아짐.
리소스가 옮겨다니는 환경 안에서 이 리소스를 똑같은 이름으로 외부의 클라이언트가 액세스 하려면 어떻게 해야 할까?
ex) mobile ip
home agent라는 애가 현재 리소스의 위치정보를 가지고 있다. 외부의 클라이언트가 home agent에게 액세스한다고 요청하기 때문에 home agent가 갖고 있는 위치정보를 이용해 응답 해줄 수 있다. 그래서 mobile host가 이동을 할때마다 바뀐주소(care of address)를 home agent에게 등록을 해야 한다. 그래서 다른 클라이언트가 연결하려할때 home agent가 알려준다. 그래서 주소가 바뀌더라도 클라이언트는 똑같은 이름으로 access할 수 있다. 그러나 delay가 있을 수 있다.
서버가 없는 p2p시스템에서 flat name을 갖고 잇고 이 name을 가진 엑세스 포인트를 찾고 싶으면 broadcast를 해야한다. 그러나 chord system에서는 broadcast는 아니고 룰을 만들어놨다. chord system에서는 링형태로 이루어져 있기 때문에 succ와 predsucc에 대한 정보만 가지고 있다. 그래서 chord system에서 naming과정은 succ와 predsucc에게 lookup 메시지를 보내서 해당하면 응답한다. 하지만 삥 돌아가는 방법 말고 점프해서 가는 방법도 있다. chord system에서 모든 노드들은 테이블 정보를 가지고 있다.(이 테이블을 finger table이라 함) 모든 피어들은 테이블 안에 lookup메시지를 다음으로 누구에게 보낼지에 대한 정보를 갖고 있다. 그래서 finger table을 갖는순간 succ,predsucc만 아는게 아니고 다른 노드에 대한 정보도 들어가 있다. 그래서 succ한테만 보내는것이 아니라 테이블을 봐서 건너뛸 부분이 있으면 건너뛸수 있음. 각 finger table의 크기는 m개의 엔트리를 갖고있다. m이라는 수는 chord system의 전체 address space를 구성할 수 있는 bit수로 이루어진다.(노드가 32개라면 log32, 즉5 bit가 된다. 5개의 엔트리) 그래서 finger table의 엔트리에는 다른 peer에 대한 주소 값이 들어가 있다.(succ(p + 2^i-1) 첫 번째 엔트리는 p+1, 두 번째는 p+2,... 그래서 2의 지수승으로 위치해 있는 놈의 정보를 알 수 있다.

즉, 내가 찾고자 하는 k가 있으면 노드 p는 자신의 finger table을 확인하고 q = FTp [j] <= k < FTp [j+1]라는 조건을 만족하는 노드에게 메시지를 보낸다. 그다음예로 28번 노드가 12라는 키값을 찾고자 한다면 28의 finger table을 본다. 그럼 4 <= k 14가 되므로 1한테 보낼 필요가 없다. 4번 노드에서는 9번 노드에게 보낸다. 9번 노드도 11에게 보낸다. 11 노드에서는 k값이 11보다 크고 첫 번째 엔트리 14보다 작으니까 12를 관리하는 애는 14 노드라는 것을 알 수 있다. 그래서 lookup과정을 건너뛸 수 있기 때문에 order of logN 복잡도 내에 찾을 수 있다.(O(logN))
그러나 단점이 있다. finger table을 계속 갱신해야 한다. 노드들이 나갔다가 들어올수 있기때문에. 그래서 참여하는 노드들이 바뀔때마다 계속 업데이트를 해야한다. 그만큼 관리하는 오버헤드도 필요하다.
주기적으로 업데이트하는 방법
노드 q는 주기적으로 자신의 succ에게 너의 predsucc가 누구냐고 물어본다.(이건 q임). 그러나 물어본 것이 내가 아니면 새로운 노드가 시스템에 들어왔다는 걸 의미하기에 바꿔야 한다. 또한 q는 finger table의 i번째 인덱스마다 q + 2^i-1에 해당하는 succ를 찾아서 lookup과정을 거쳐야 한다. 또한 각각의 노드들도 주기적으로 나의 predsucc가 살아있는지 확인해야 한다. 만약 predsucc가 나갔으면 나의 prdsucc는 unknown으로 설정한다. 이러한 오버헤드를 무시할 수 없다.
flat naming : hierarchical approaches
hierarchical 하게 구성한다는 것은 네트워크를 작은 단위의 도메인으로 나누 나는 것이다. 그래서 도메인을 하이라키컬하게 구성을 해놓으면 네트워크안에서 flat name을 갖는 리소스를 찾을때 효율성을 높일 수 있다. lowest-level( leaf) domain이라는 것은 주로 랜환경을 의미한다. 각각의 domain이 모여서 건대의 네트워크, 다른 대학의 네트워크가 합쳐져서 대한민국의 네트워크가 구성되는것 처럼 하이라키컬하게 구성하겠다는 것이다. 그리고 도메인 안에 있는 리소스들에 대한 정보를 가지고 있는 특수 노드(디렉터리 노드)가 있고 이 노드는 자기가 관리하는 도메인안에 있는 모든 리소스들의 이름 정보를 알고 있다. 그래서 도메인안에 있고 내가 이름을 알고있는 리소스를 찾고싶을때 자기가 속한 디렉토리 노드에게 물어보자. 만약 내가 찾고자 하는 리소스가 나와같은도메인 안에 있다면 바로 응답을 해줄것이다. 만약 없으면 디렉토리노드가 자신의 상위 디렉토리 노드로 넘겨준다. 못 찾을 경우 모든 노드들의 정보를 알고 있는 루트 디렉터리까지 간다. 그러나 모든 엔티티에 대해서 모든 address에 대한 정보를 다 갖고 있는 건 아니다.
그럼 어떻게 엔티티의 이름과 주소정보를 저장할까? 찾고자 하는 엔티티가 D라는 도메인에 속했다면 그 엔티티에 대한 현재 위치 정보는 location record라는 형태로 관리가 된다. 그래서 E의 전체 주소정보를 N'이 다 갖고 있는 것이 아니고 N에게 물어보라는 포인터만 가지고 있다. 그래서 가능한 한 유지하는 정보의 양을 줄이고자 하는 목적이 있다. 그래서 E 엔티티에 직접적으로 연결돼 있는 도메인의 디렉터리 노드만 정보를 가지고 있고 상위 디렉토리 노드들은 말단 엔티티의 정보를 포인터 형태로만 가지고 있다. 이런 식으로 구성하면 flat naming에서 broadcast를 항상 하지 않아도 된다.


이러한 하이라키컬하게 사용하면 multiple address를 관리할 수 있게 된다. multiple address는 리소스가 복제되었을 때 어떤 한 엔티티의 주소가 하나만 있는 게 아니고 여러 주소를 가지고 있어서 여러 pc가 같은 리소스를 접근할 수 있다는 걸 의미



hierarchical 과정에서 중요한 것이 뭐냐?
이름을 갖는 엔티티를 찾아가는 과정을 내가 속한 엔티티를 먼저 찾아가고(locality를 활용) 여기서도 없으면 점점 범위를 늘려서 찾는다. 하이라키컬하게 구성을 유지하기 위해서 엔티티가 추가된다면 그 도메인에 대한 정보를 디렉터리 노드들이 추가를 한다.

Structured naming
flat처럼 아무 의미 없는 게 아니고 이름 자체에 어떤 구조(룰)가 있는 것을 의미
새로운 이름을 짓고자 한다면 주어진 name space에서 정해진 규칙 안에서 이름을 지어야 한다.(노드와 에지로 구성된 그래프의 형태로 이름이 지어진다.) 여기서도 루트노드가 있고 말단 노드가 있다. flat name에서의 하이라키컬한것은 동일하나, flat name에서는 이름을 관리하는 디렉터리 노드들이 하이라키컬하게 구성되어있지만 structured 에서는 엔티티의 이름 자체가 하이라키컬하게 구성되어 있다.

name resolution : 어떤 이름이 인풋으로 주어졌을 때 이 이름의 address를 찾아가는 과정
Alias : 같은 엔티티를 지칭하는 또 다른 이름(ex. 위의 그림의 n5 두 가지 모드 hardlink)
symbolic link :

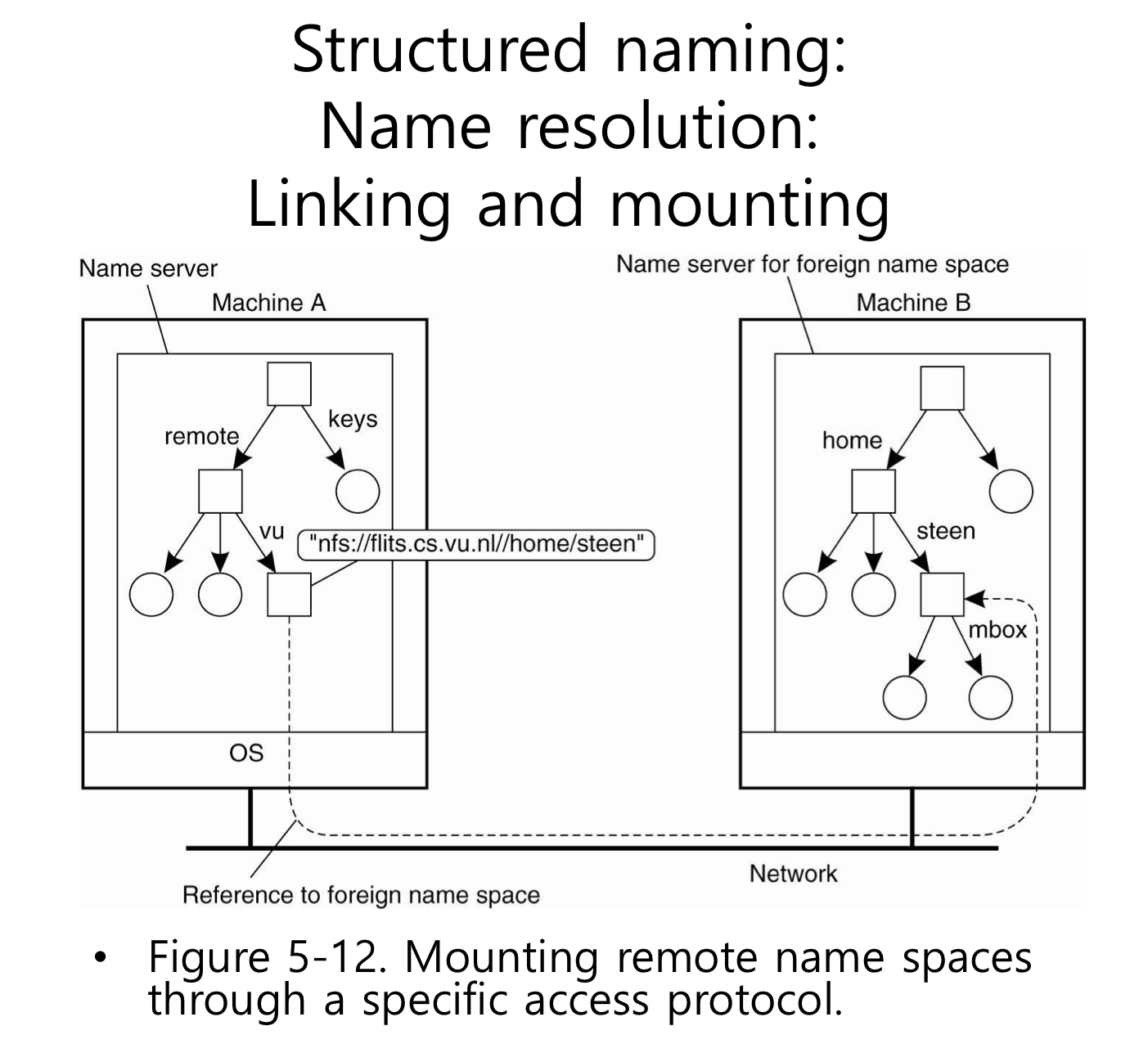
또한 서로 다른 name space를 연결해서 name resolution을 할 수 도 있다.
그래서 두 컴퓨터에서 사용하는 name space를 연결시키는 방법이 필요하다. 여기서 연결한다는 개념을 mount 한다고 한다.
mount point : 원래 해당 노드의 ID를 저장하고 있는 디렉터리 노드가 mount point이다.
mounting point : 다른 컴퓨터에 있는 name space의 특정 디렉토리 지점이라고 한다.
그래서 마운트 포인트와 마운팅 포인트는 서로 연결이 돼야 한다. 연결하기 위해서 3가지가 필요하다.
1. 원격지의 name space에 access 하기 위한 프로토콜이 정의되어 있어야 한다.
2. 서버정보
3. mounting point의 정보
이 3가지를 잘 사용하는 예시 URL
또 다른 예시 : 노트북을 쓰다가 다른 원격지에 있는 파일을 액세스 하고 싶을 때, 클라이언트와 서버 모두 원격지에 있는 파일을 액세스 하기 위해서 NFS(network file system)라는 프로토콜을 사용하자. 클라이언트는 내가 찾고자 하는 파일의 경로를 URL형태로 줄 수 있다. ex) nfs://flits.cs.vu.nl/home/steen 여기서 nfs는 nfs 프로토콜을 사용한다는 것을 의미한다. 그다음은 domain name(서버)를 제시한다. 그 뒷부분이 마운팅 포인트에 대한 정보이다.
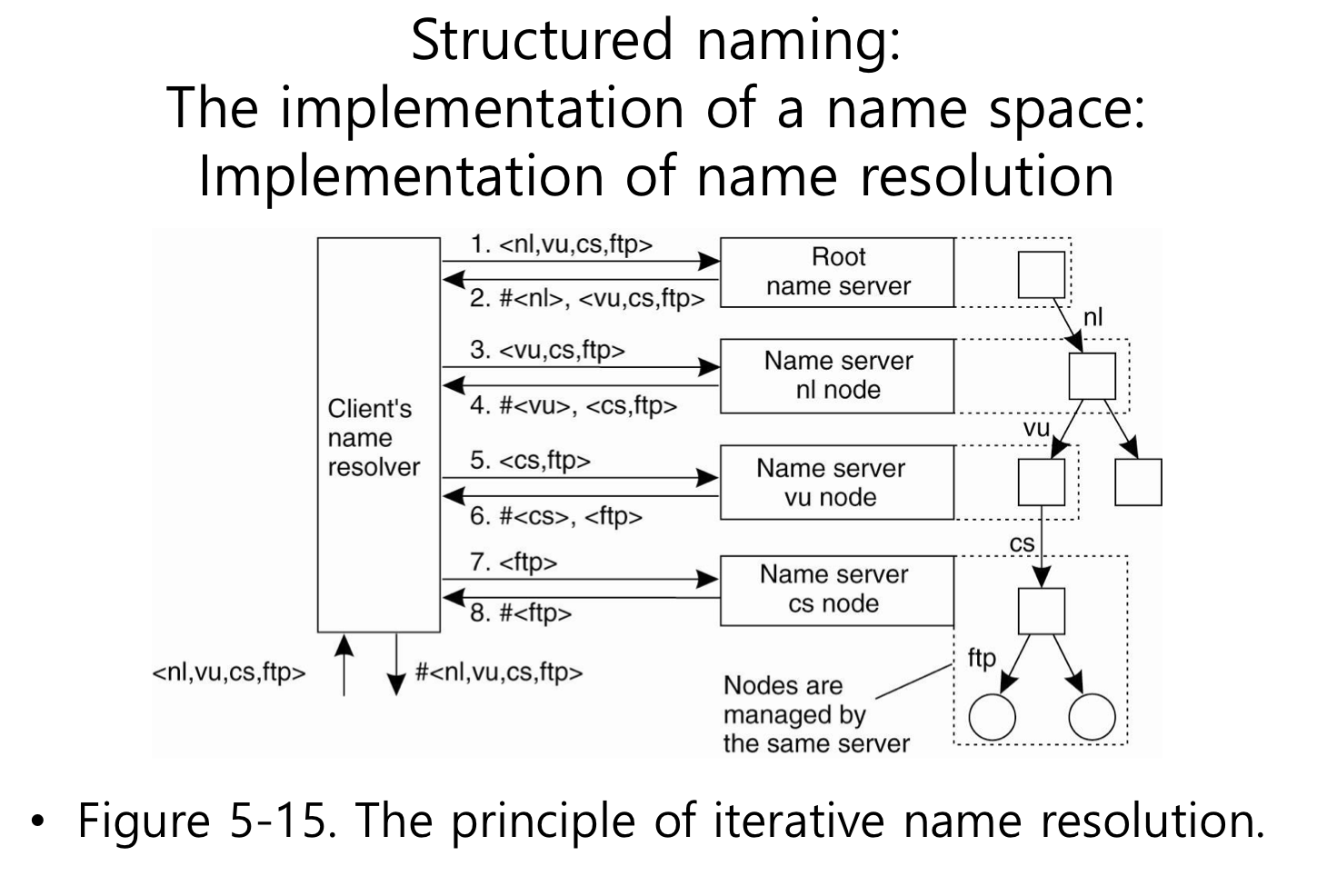
flat name에서 루트 노드는 모든 엔티티에 대한 주소정보는 알지 못하더라도 엔티티의 주소를 찾아가려면 누구한테 물어봐라라고 하는 정보는 다 있었다. 유사하게도 구조적 name에서도 루트 naming server는 루트 밑에 바로 하위 레벨의 name space를 관장하는 name server들에 대한 정보를 알고 있다. 그러나 이름 자체에 어떤 name server한테 물어보면 된다는 정보가 다 들어 있기 때문에 flat name처럼 어떤 놈한테 물어봐라라는 정보를 다 유지할 필요는 없다. 그래서 naming server의 layer를 세 가지로 나눌 수 있다.


트리구조의 그림을 표로 나타내어 각 계층을 비교해 보자.

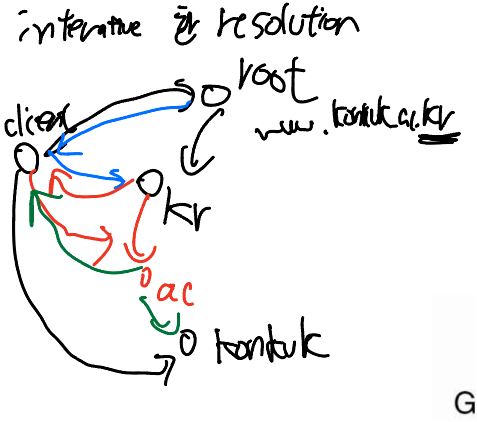
naming resolution을 두 가지 방법으로 나눠보자. (interative와 recursive방식으로)


그럼 인터렉티브 하게 할 건지 리컬시브하게 할건지 정해야 하는데 어떻게 하는 것이 좋을까?
recursive 한 방식을 쓰게 될경우 서버하나가 처리해야할일이 interative보다 많다. 리퀘스트를 요청하고 아래놈이 나머지 과정을 다 처리해서 응답이 올때까지 기다렸다가 응답을 받아서 줘야한다. 즉, recursive는 resolution의 나머지 과정을 직접 담당을 해야한다. 이러한 측면에서 볼때 recursive한 방식은 더 높은 퍼포먼스를 요구해야한다. 이러한 방식은 부담이 많이 들기 때문에 global layer에 있는 서버들은 recursive한 방식은 잘 사용하지 않는다. 장점으로는 캐싱을 효율적으로 사용할 수 있다. 모든 layer에 있는 네임 서버들이 클라이언트로부터 온 결과를 각자 받기 때문에 필요한 경우 각 정보들을 캐시 할 수가 있다. 그래서 자주 요청되는 네임들은 밑에 애한테 물어볼 필요가 없다. interative는 서버들 간의 상호작용이 없기 때문에 중간노드들이 결괏값에 대한 것을 알지 못한다. 또한 interative 한 방식보다 recursive가 커뮤니케이션 비용이 적을수 있다.

interative한 방식을 사용했을 경우에는 client name resolver에서만 캐시가 가능하고 네임 서버들이 캐시를 할 일은 없다. 그래서 많은 경우에 loal name server를 사용하는 것이 일반적이다. 이 서버가 name resolver의 역할을 해준다. 그래서 우리들이 사용하는 DNS request는 local name server로 간다. 그래서 local name server가 모든 요청들을 받아서 처리를 해준다. 캐시 된 데이터가 있다면 그 캐시값을 주기도 하고 아니면 직접 resolution과정을 거쳐서 클라이언트에게 알려주기도 한다. interative과정은 매번 클라이언트는 서로 다른 네임서버들에게 직접적으로 리퀘스트를 날려야 한다. 응답이 오면 최종결과를 받을 때까지 다음 서버에 묻고 또 다음서버에 물어본다. 그래서 커뮤니케이션 비용이 recursive 한 경우보다 크다. 장점으로는 recursive보다 부하가 크지 않다. 그렇기 때문에 서버입장에서는 관리하기에 더 편할 수 있다.
attribute-based naming
룰에 의해서 이름을 만들자. 그런데 이 룰은 내가 찾고자 하는 리소스의 attribute(속성)를 가지고 직접 리소스를 지칭할 수 있도록 하자. 그래서 내가 찾고자 하는 리소스의 이름은 리소스의 속성을 나열하면 된다. structured name은 지칭을 하게 되면 이 path를 갖는 애가 딱 한놈으로 매핑이 된다. 그런데 attribute에서는 하나의 이름으로 여러 놈을 지칭할 수 있게 된다. 그래서 공통된 특성을 갖는 여러 리소드 들을 한 번에 찾고 싶을 때 attribute을 쓰면 효율적이지만 structured에 비하면 복잡해진다. 왜냐하면 attribute방식으로 찾고 싶을 때 어떤 규칙이 없으면 하나하나 다 찾아야 하기 때문. flat이나 structured 같은 경우에는 유니크하고 location independent 한 방법으로 엔티티를 지칭을 했다면 attribute는 유니크하지 않고(여러 개가 될 수 있음) 인간에게 친밀하게 이름을 지을 수 있도록 해줬다. 그래서 내가 찾고자 하는 리소스가 있다면 그 리소스의 특징을 나열해 주면 된다. 그럼 속성들을 어떻게 표현할까? 바로 attribute의 이름과 그 속성의 값의 pair로 구성을 한다.
attribute 기반 네이밍과 유사하게 사용하는 대표적인 예로 디렉터리 서비스가 있다.
그럼 속성이라는 것은 어떻게 정의를 할까? 이것도 표준이 있으면 좋을 것이다. 그래서 어떤 룰이 없다면 시스템 별로 제멋대로 속성을 정의할 수 있기 때문에 RDF(resource description franewrok)로 정의하자. 그래서 RDF로 엔티티의 속성을 표시할 수 있다. RDF에서 리소스는 주어, 동사, 목적어의 형태인 triplets으로 나타낼 수 있다. ex) (person, name, alice) : 내가 찾고자 하는 리소스는 person인데 이름이 alice이다. 그래서 이런식으로 하게되면 structured와는 다르게 찾는 비용은 크다. 왜냐하면 이런 특성을 갖는 엔티티가 여러개가 나올수 있기 때문이다. 반면에 structure는 한놈만 나오기 때문. 그래서 exhaustive search가 필요하다. 그래서 exhaustive search를 해야하니까 비용을 어떻게 줄일까? 생각을 하다보니 찾고자하는 name space를 하이라키컬하게 구성을 해보자. 그러면 좀더 효율적으로 찾을 수 있을 것이다. LDAP(lightweight directory access protocol)라는 프로토콜이 이런 정책을 사용한다. attribute는 디렉토리 서비스라고 표현이 된다고 했기 때문에 LDAP는 attribute를 사용하는 프로토콜의 일종이다. 그래서 가능한한 exhaustive search를 줄이기 위해서 LDAP에서는 name space를 하이카리컬(계층적)하게 구성을 한다. LDAP에서 디렉토리 서비스는 디렉토리 엔트리라고 하는 레코드를 유지하고 있어서 여러 노드들이 마치 structured에서 네임 서버들이 분산되어 계층적으로 구성이 된것처럼 디렉토리 엔트리가 찾고자하는 노드의 정보를 분산해서 관리를 한다.

LDAP 프로토콜에 사용되는 용어들
DIB(directory information base) : LDAP에서 유지하는 전체 DB 즉, attribute이름과 위치 정보들의 총집합이라고 한다.
RDN(relative distinguished name) : 각각의 attribute를 RDN이라고 부른다. 위의 표에 있는 각각을 RDN이라고 함.
DIT(directory information tree) : DIB를 효율적으로 찾기 위해서 트리형태로 조직을 하겠다는 뜻. LDAP naming 그래프라고 표현하기도 한다.

DSA(directory service agent) : LDAP에서 naming resolution을 해주는 naming서버를 이름 지은 것이다.
DUA(directory user agent) : 클라이언트를 의미한다. DUA가 내가 찾고자 하는 리소스를 찾아달라고 요청하면 DSA가 찾아줄 것이다. DUA가 날릴 수 있는 메시지의 형태는 structured에서는 할 수 없었던 것을 attribute에서는 할 수 있다.
ex) search("&C=NL)(O-vrije unversiteit)(OU=*)(CN=main Server)") 여기서 * 은 모든 학과를 의미.
이러한 경우 때문에 디렉터리서비스에서 설치 비용이 비싸다.(속성으로 날아온 값이 유일하지 않을 수 있기 때문)
그러나 flat이나 structured는 내가 찾고자 하는 리소스의 네임을 알아야 했지만 attribute는 이름자체가 속성이기 때문에 정확한 이름을 모르더라도 일부속성만 가지고 리소스를 찾을 수 있게 된다.
attirbute기반 naming에서 LDAP라고 하는 프로토콜상에는 서버가 있다. 그래서 서버 쪽에 이런 속성을 갖는 엔티티를 찾아달라고 요청을 서버에게 물어본다.(centralized 구조) 이러한 것도 decentralized 하게 구성해 보자라는 연구도 있다. 특정서버 없이 P2P형식으로 해보자라는 뜻. 그럼 엔티티를 어떤 놈이 어떻게 관리할지에 관한 룰이 필요하다. (ex. chord system처럼 해쉬값을 부여하기) 얘도 결국에는 해쉬값을 사용한다. 찾고자 하는 속성이 있다면 그 속성에 해당하는 해쉬값을 만들자. 이것을 AVTree(attribute value tree)로 만들자. AVTree : 어떤 속성과 값이 있으면 내가 찾고자 하는 속성과 값으로 표현을 해두면 그것을 트리형태로 바꿔서 각트리의 에지 별로 해쉬값을 설정하겠다는 의미.



'Computer Science > 분산시스템' 카테고리의 다른 글
| [분산 시스템] Consistency and Replication (0) | 2024.06.10 |
|---|---|
| [분산 시스템] Synchronization (0) | 2024.06.03 |
| [분산 시스템] Communication (0) | 2024.04.15 |
| [분산 시스템] Process (0) | 2024.04.05 |
| [분산 시스템] Architectures (0) | 2024.03.31 |