빅데이터가 폭발적으로 증가하는 시대를 맞이하면서 데이터를 수집하는 것과 저장하는 기술의 급속한 발전으로 빅데이터라는 용어가 나오게 되었다.
이렇게 많은 양의 데이터를 분석해서 actionable한 insights를 도출하는 것이 중요해졌다.
빅데이터의 4Vs
- Volume(양) : 저장해야 하는 데이터의 방대한 양을 의미한다. ex) 2.5GB
- Velocity(속도) : 데이터 생성과 처리 속도가 빠르다. ex) 초당 99000건의 검색
- Variety(다양성) : 데이터의 형식이 다양하다. ex)이미지, 비디오, 오디오 등
- Veracity(진실성) : 데이터의 품질과 신뢰성을 나타낸다.
Motivating Challenges
데이터 사이언스와 마이닝에서 마주하는 주요한 도전 과제들
- Scalability(확장성) : 현재의 데이터 셋은 너무 크기 때문에 큰 데이터를 다룰 수 있어야 한다.
- 기하급수적인 검색 문제들을 다루기 위한 특별한 검색 전략
- 개인 기록에 효율적으로 access하기 위한 Novel data 구조
- disk-based의 Out-of-core 알고리즘
- 샘플링
- 병렬 및 분산 알고리즘
- High Dimensionality(고차원성) : 데이터는 수백~수천 개의 피처들을 가질 수 있다.
- 발생가능한 문제들
- curse of dimensionality(차원의 저주) : 차원이 많을수록 알고리즘의 성능이 하락함
- 계산 복잡성 증가
- 발생가능한 문제들
- Heterogenous data(이질적인 데이터) : 데이터셋은 다른 타입의 데이터를 포함할 수 있다. ex) 이미지, 오디오 등
- 데이터 마이닝 기술은 데이터들 간의 관계를 고려해야 한다.
- Data distribution(데이터 분산성) : 데이터가 여러 장소에 분산될 수도 있다. 이를 대처하기 위해서 기술이 필요
- 분산 알고리즘을 통해서 여러 장소에서 작업을 나누고 각 장소에서 얻은 결과를 통합
데이터 사이언스와 데이터 마이닝
첫번째 관점
- Exploration(탐색) : 데이터의 패턴을 식별하고 복잡한 정보를 이해하는 과정(시각화나 통계자료 이용)
- Inference(추론), Validation(검증) : 새로운 데이터에도 관찰된 패턴이 나타날 수 있는지 확인하고 검증하는 과정
- Prediction(예측) : 머신러닝이나 딥러닝을 사용해서 새로운 데이터에서 대한 예측을 수행
이러한 방법을 조합해서 raw data에서 의미 있는 insights를 얻어내자
두 번째 관점
- Descriptive Methods(서술적 방법) : 사람이 이해할 수 있는 패턴을 찾고 데이터에서 어떤 일이 발생하는지 설명
- Predictive Methods(예측적 방법) : 알려진 변수를 사용해서 아직 알려지지 않은 값을 예측
이러한 방법은 raw data를 meaningful insights로 변환하는데 도와준다.
결론은 둘다 거대한 데이터셋에서 쓸모 있는 정보를 얻어내기를 위함이다.
데이터 사이언스와 데이터 마이닝 차이점
| 데이터 사이언스 | 데이터 마이닝 |
| (un)(semi)structured한 타입의 모든 데이터를 다룸 | structured한 형태의 데이터를 주로 다룸 |
| 데이터 마이닝의 super set | 데이터 사이언스의 subset |
| 과학적인 목적으로 사용 | business적인 목적으로 사용 |
| 데이터의 과학적 분석에 초점 | 데이터의 processes과정에 초점 |
요약
- 데이터 사이언스 : 머신러닝 및 데이터 중심의 인공지능
- 데이터 마이닝 : 예측 분석
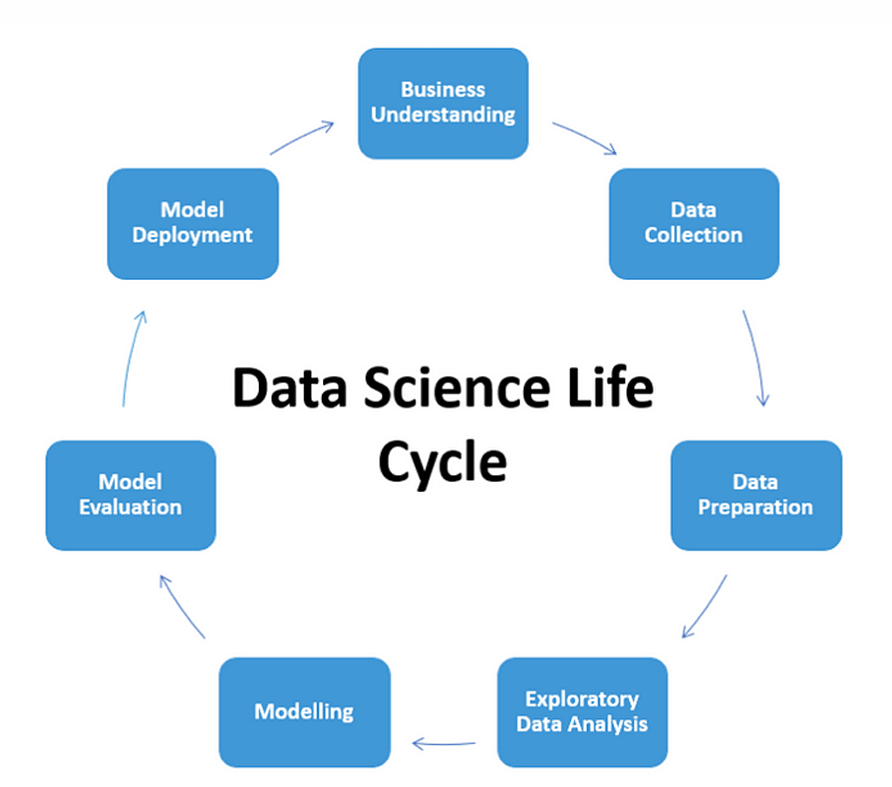
- Define Problem Statement : 해결하려는 문제를 명확하게 정의(이해)하는 단계 ex) 수익을 증가시키자, 가격을 예측하자
- Data Collection and Preparation : 문제를 해결하기 위해 데이터를 수집하는 단계이고 수집된 데이터는 결측치 제거 등을 통한 작업으로 데이터를 정제한다.
- Exploratory Data Analysis(=understanding the data) : 데이터를 분석해서 유용한 insights를 도출하고 이해도를 높이는 과정이다. 이과정을 생략한다면 부정확한 모델이 나올 수 있기에 시각화나 통계를 통해서 분석하자.
- Building the Model : 데이터를 분석해서 모델을 구축하는 과정이다. 확률과 추론 통계를 통해서 변수 간의 관계를 파악하는 것이 중요하다.
- Understand the World(=Using the model) : 구축된 모델을 사용해서 세계에 대한 이해를 높이고 데스트를 통해서 추론 및 예측을 하는 과정이다.
- Data Communication : 분석결과를 전달하는 과정이다. 결과를 쉽게 설명하고 어떻게 분석했는지를 공유하는 단계
Core Ideas
- Classification(분류) and Regression(회귀) : 분류는 discrete한 변수 예측에 사용된다. (이메일이 스팸인지 아닌지) 회귀는 continuous한 변수 예측에 사용된다 (주택 가격 예측)
- Association Analysis(연관 분석) : 데이터에서 강하게 연괸된 특징을 발견하는 방법이다. ex) market basket analysis "빵을 사는 사람들이 버터를 같이 살 확률이 높다."
- Cluster Analysis(Clustering) : 군집 분석은 비슷한 특성을 가진 데이터를 그룹으로 묶는 기법이다.
- Content-based Recommendations : 콘텐츠를 기반으로 추천하는 방법은 과거에 선호했던 것과 유사한 항목을 추천하는 방법이다.
- Collaborative Filtering(협업 필터링) : 협업 필터링은 사용자의 평가 패턴을 기반으로 비슷한 취향을 가진 사용자그룹을 찾아서 그 그룹의 선호도를 바탕으로 항목을 추천한다.
- Latent Factor Models(잠재 요인 모델) : 사용자-항목 상호작용 행렬을 잠재 요인으로 분해해서 추천을 수행하는 방법
- Bag of Words(BoW) and TF-IDF(Term Frequency - Inverse Document Frequency) : BoW는 문서를 단어들의 집합으로 나타내는 방법으로 순서는 무시하고 빈도만 고려하는 것, TF-IDF는 자주 등장하는 단어의 가중치는 낮추고, 적게 등장하는 단어는 가중치를 높여서 중요한 단어를 강조하는 방법
- N-grams : 텍스트를 연속된 단어 그룹으로 나눠서 분석하는 방법이다.

N이 2라면 두개 단어 뒤에 나올 단어를 예측하는 방식 - Topic Modeling : 대량의 텍스트 데이터에서 숨겨진 주제나 토픽을 찾는 기법
- Word Embedding : Word2Vec 기술을 사용해서 특정 단어가 주변 단어들과 얼마나 자주 등장하는지 분석해서 단어의 의미를 파악하는 방식이다.
- Node/Edge/Graph-level Feature Extraction(Handcrafted Feature Engineering) : 그래프에서 노드, 엣지, 그래프 수준에서 직접 설계된 특성을 사용해서 분석하는 방법
- Node-level Feature Extraction(Node Centrality)
- Edge-level Feature Extraction(Local Neighborhood Overlap)
- Edge-level Feature Extraction(Global Neighborhood Overlap)
- Graph-level Feature Extraction(Graphlet Kernel)
- Graph-level Feature Extraction(Weisfeiler-Lehman Kernel)
- PageRank : 웹페이지의 중요성을 평가하는 알고리즘이다.
- Graph Representation Learning : 그래프의 각 노드를 저차원 공간에 매핑하여 유사한 노드들이 가까이 위치하도록 학습하는 방식
- DeepWalk(Random Walk) : 그래프에서 노드 간의 관계를 학습한다. 즉, 그래프 상에서 두 노드 간의 연관성을 측정해서 임베딩을 최적화함
- Graph Neural Networks(그래프 신경망) : 노드와 이웃 노드 간의 관계를 학습해서 그래프 구조를 반영한 임베딩을 생성
- Graph-based Recommendation : 그래프 기반 추천 시스템은 이중 그래프 형태로 사용자와 아이템 간의 관계를 모델링한다. 이 그래프 구조를 통해서 사용자-아이템 간의 고차원적인 연결성을 추출한다.
- Graph-based Text Mining : 문서와 단어 간의 공동 출현 관계를 그래프로 나타내는 방법이다. 이 방법은 텍스트에서 문맥 정보를 통합해서 단어 간의 연결관계를 통해 더 깊은 의미를 파악할 수 있다.
'Computer Science > 데이터 사이언스' 카테고리의 다른 글
| Data Mining Processing and Visualization (0) | 2024.09.24 |
|---|